Result Storage
This notebook will show how to store pypesto result objects to be able to load them later on for visualization and further analysis. This includes sampling, profiling and optimization. Additionally, we will show how to use optimization history to look further into an optimization run and how to store the history.
After this notebook, you will…
know how to store and load optimization, profiling and sampling results
know how to store and load optimization history
know basic plotting functions for optimization history to inspect optimization convergence
[1]:
# install if not done yet
# %pip install pypesto --quiet
Imports
[2]:
import logging
import tempfile
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import Markdown, display
import pypesto.optimize as optimize
import pypesto.petab
import pypesto.profile as profile
import pypesto.sample as sample
import pypesto.visualize as visualize
mpl.rcParams["figure.dpi"] = 100
mpl.rcParams["font.size"] = 18
# set a random seed to get reproducible results
np.random.seed(3142)
%matplotlib inline
0. Objective function and problem definition
We will use the Boehm model from the benchmark initiative in this notebook as an example. We load the model through PEtab, a data format for specifying parameter estimation problems in systems biology.
[3]:
%%capture
# directory of the PEtab problem
petab_yaml = "./conversion_reaction/conversion_reaction.yaml"
importer = pypesto.petab.PetabImporter.from_yaml(petab_yaml)
problem = importer.create_problem(verbose=False)
2026-03-18 12:59:28.035 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - PEtab mapping: ({}, {'k1': 'k1', 'k2': 'k2'}, {}, {'k1': 'log', 'k2': 'log'})
2026-03-18 12:59:28.035 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Fixed parameters pre-equilibration: {}
2026-03-18 12:59:28.036 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Fixed parameters simulation: {}
2026-03-18 12:59:28.036 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Variable parameters pre-equilibration: {}
2026-03-18 12:59:28.037 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Variable parameters simulation: {'k1': 'k1', 'k2': 'k2'}
2026-03-18 12:59:28.038 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Merged: {'k1': 'k1', 'k2': 'k2'}
1. Filling in the result file
We will now run a standard parameter estimation pipeline with this model. Aside from the part on the history, we shall not go into detail here, as this is covered in other tutorials such as Getting Started and AMICI in pyPESTO.
Optimization
[4]:
%%time
# create optimizers
optimizer = optimize.FidesOptimizer(
verbose=logging.ERROR, options={"maxiter": 200}
)
# set number of starts
n_starts = 10 # usually a larger number >=100 is used
# Optimization
result = pypesto.optimize.minimize(
problem=problem, optimizer=optimizer, n_starts=n_starts
)
CPU times: user 229 ms, sys: 6.08 ms, total: 235 ms
Wall time: 235 ms
[5]:
display(Markdown(result.summary()))
Optimization Result
number of starts: 10
best value: -25.356200472112807, id=0
worst value: 2632.872853377001, id=6
number of non-finite values: 0
execution time summary:
Mean execution time: 0.023s
Maximum execution time: 0.043s, id=1
Minimum execution time: 0.003s, id=6
summary of optimizer messages:
Count
Message
8
Converged according to fval difference
2
Trust Region Radius too small to proceed
best value found (approximately) 7 time(s)
number of plateaus found: 2
A summary of the best run:
Optimizer Result
optimizer used: <FidesOptimizer hessian_update=default verbose=40 options={‘maxiter’: 200}>
message: Trust Region Radius too small to proceed
number of evaluations: 23
time taken to optimize: 0.040s
startpoint: [ 4.20939637 -0.95036979]
endpoint: [-0.25416788 -0.60834114]
final objective value: -25.356200472112807
final gradient value: [ 7.49197054e-06 -7.61052633e-06]
final hessian value: [[1709.63193844 -881.86256372] [-881.86256372 538.50967455]]
Profiling
[6]:
%%time
# Profiling
result = profile.parameter_profile(
problem=problem,
result=result,
optimizer=optimizer,
profile_index=np.array([0, 1]),
)
CPU times: user 1.48 s, sys: 21.3 ms, total: 1.51 s
Wall time: 1.5 s
Sampling
[7]:
%%time
# Sampling
sampler = sample.AdaptiveMetropolisSampler()
result = sample.sample(
problem=problem,
sampler=sampler,
n_samples=1000, # rather low
result=result,
filename=None,
)
Elapsed time: 0.5106699069999996
CPU times: user 504 ms, sys: 8.83 ms, total: 513 ms
Wall time: 512 ms
2. Storing the result file
We filled all our analyses into one result file. We can now store this result object into HDF5 format to reload this later on.
[8]:
# create temporary file
fn = tempfile.NamedTemporaryFile(suffix=".hdf5", delete=False)
# write the result with the write_result function.
# Choose which parts of the result object to save with
# corresponding booleans.
pypesto.store.write_result(
result=result,
filename=fn.name,
problem=True,
optimize=True,
profile=True,
sample=True,
)
As easy as we can save the result object, we can also load it again:
[9]:
# load result with read_result function
result_loaded = pypesto.store.read_result(fn.name)
As you can see, when loading the result object, we get a warning regarding the problem. This is the case, as the problem is not fully saved into hdf5, as a big part of the problem is the objective function. Therefore, after loading the result object, we cannot evaluate the objective function anymore. We can, however, still use the result object for plotting and further analysis.
The best practice would be to still create the problem through petab and insert it into the result object after loading it.
[10]:
# dummy call to non-existent objective function would fail
test_parameter = result.optimize_result[0].x[problem.x_free_indices]
# result_loaded.problem.objective(test_parameter)
[11]:
result_loaded.problem = problem
print(
f"Objective function call: {result_loaded.problem.objective(test_parameter)}"
)
print(f"Corresponding saved value: {result_loaded.optimize_result[0].fval}")
Objective function call: -25.35619987137794
Corresponding saved value: -25.356200472112807
To show that for visualizations however, the storage and loading of the result object is accurate, we will plot some result visualizations.
3. Visualization Comparison
Optimization
[12]:
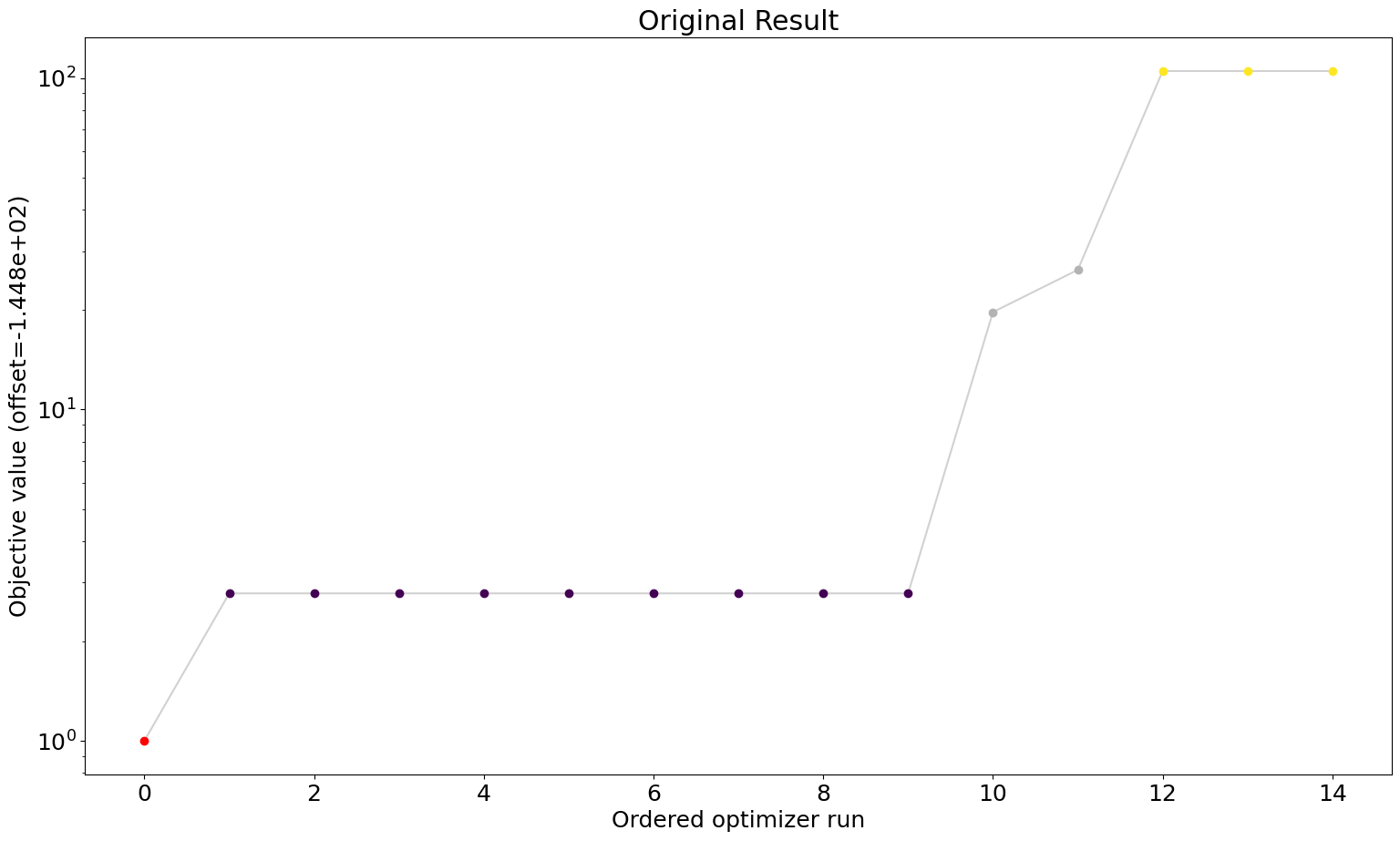
# waterfall plot original
ax = visualize.waterfall(result)
ax.title.set_text("Original Result")
[13]:
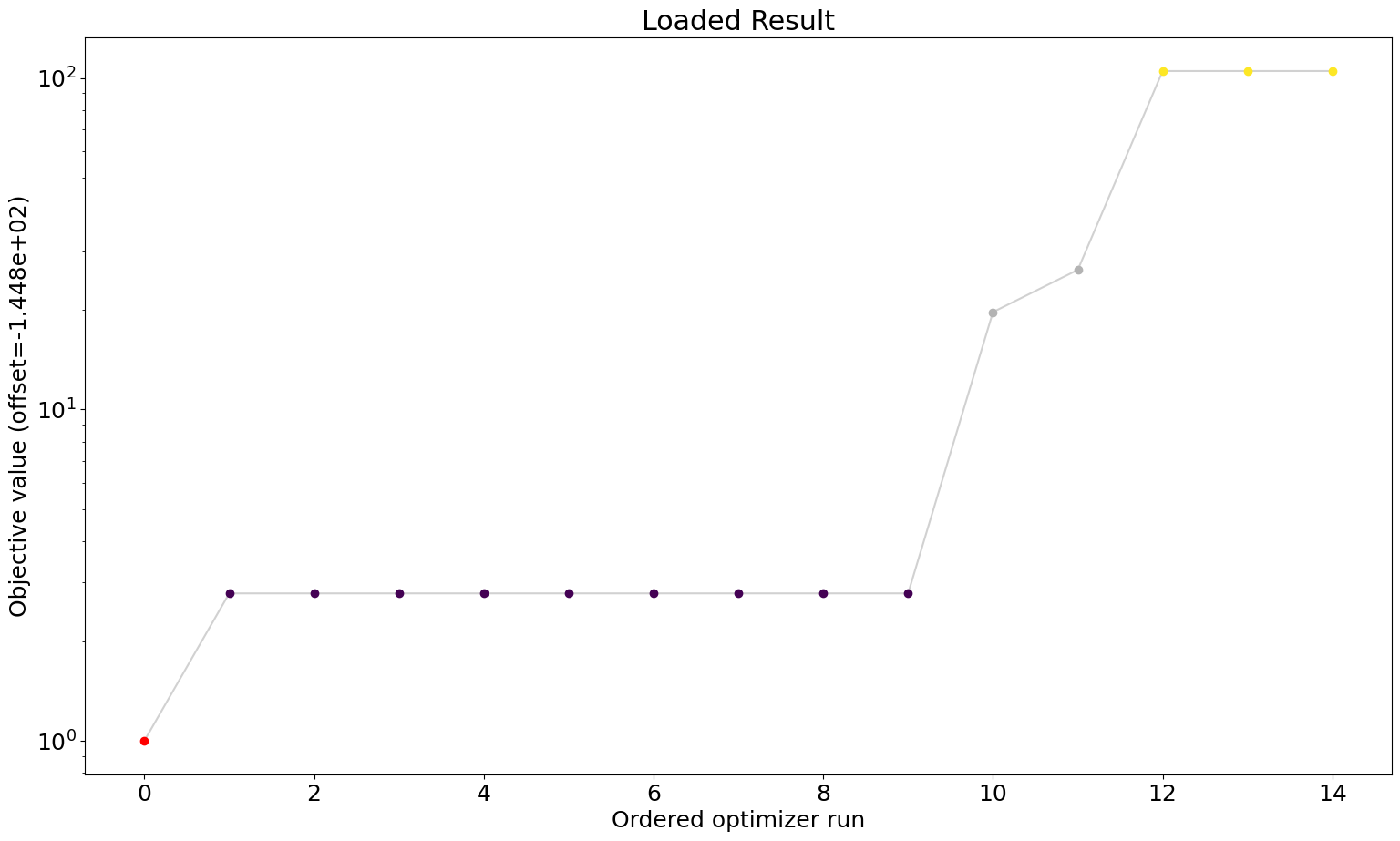
# waterfall plot loaded
ax = visualize.waterfall(result_loaded)
ax.title.set_text("Loaded Result")
Profiling
[14]:
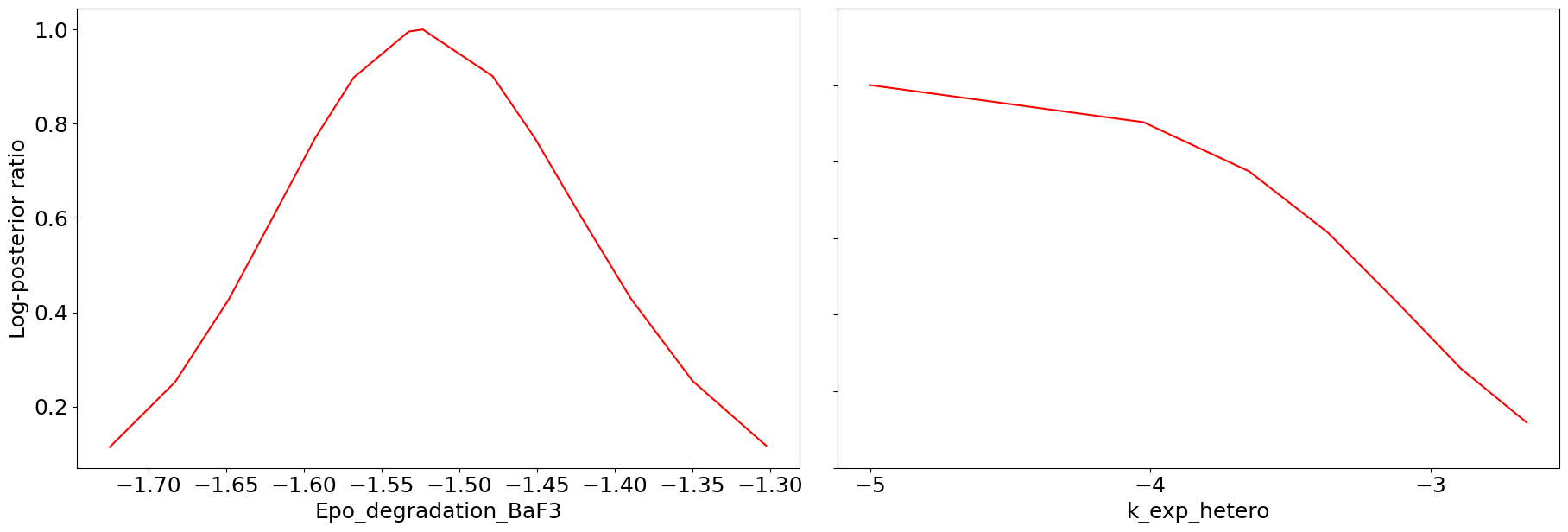
# profile plot original
ax = visualize.profiles(result)
[15]:
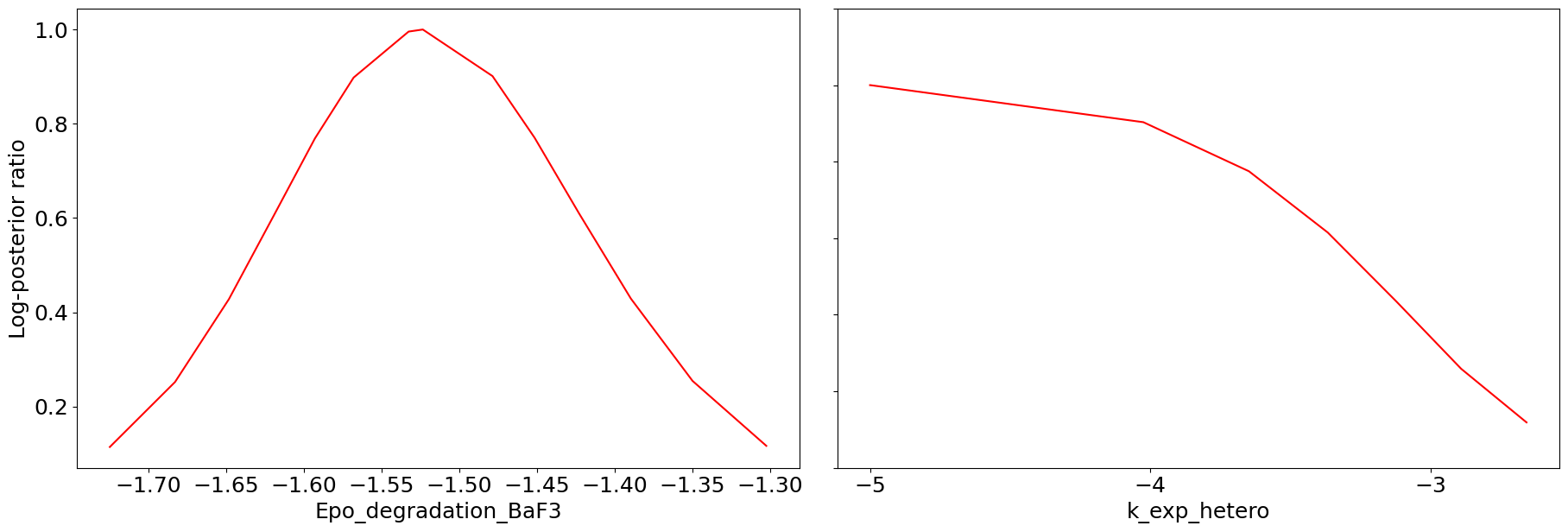
# profile plot loaded
ax = visualize.profiles(result_loaded)
Sampling
[16]:
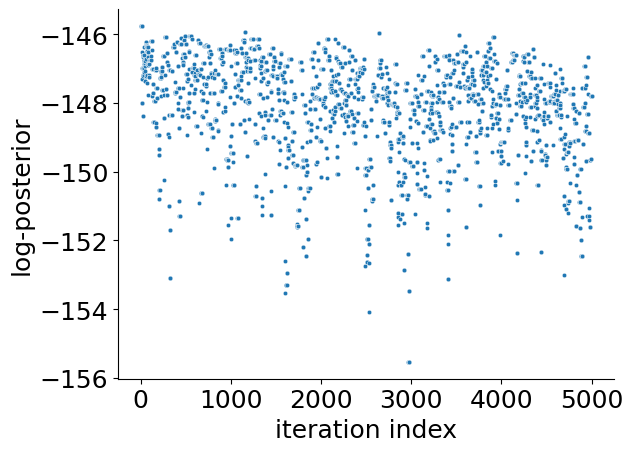
# sampling plot original
ax = visualize.sampling_fval_traces(result)
/home/docs/checkouts/readthedocs.org/user_builds/pypesto/envs/stable/lib/python3.13/site-packages/pypesto/visualize/sampling.py:78: UserWarning: Burn in index not found in the results, the full chain will be shown.
You may want to use, e.g., `pypesto.sample.geweke_test`.
_, params_fval, _, _, _ = get_data_to_plot(
[17]:
# sampling plot loaded
ax = visualize.sampling_fval_traces(result_loaded)
/home/docs/checkouts/readthedocs.org/user_builds/pypesto/envs/stable/lib/python3.13/site-packages/pypesto/visualize/sampling.py:78: UserWarning: Burn in index not found in the results, the full chain will be shown.
You may want to use, e.g., `pypesto.sample.geweke_test`.
_, params_fval, _, _, _ = get_data_to_plot(
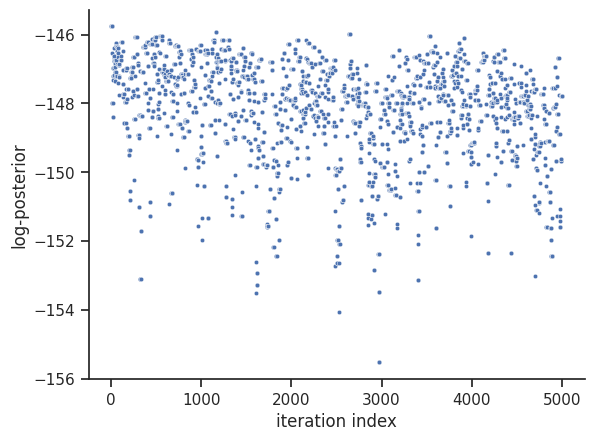
We can see that we are perfectly able to reproduce the plots from the loaded result object. With this, we can reuse the result object for further analysis and visualization again and again without spending time and resources on rerunning the analyses.
4. Optimization History
During optimization, it is possible to regularly write the objective function trace to file. This is useful, e.g., when runs fail, or for various diagnostics. Currently, pyPESTO can save histories to 3 backends: in-memory, as CSV files, or to HDF5 files.
Memory History
To record the history in-memory, just set trace_record=True in the pypesto.HistoryOptions. Then, the optimization result contains those histories:
[18]:
%%time
# record the history
history_options = pypesto.HistoryOptions(trace_record=True)
# Run optimizations
result = optimize.minimize(
problem=problem,
optimizer=optimizer,
n_starts=n_starts,
history_options=history_options,
filename=None,
)
CPU times: user 224 ms, sys: 4.9 ms, total: 229 ms
Wall time: 228 ms
Now, in addition to queries on the result, we can also access the history.
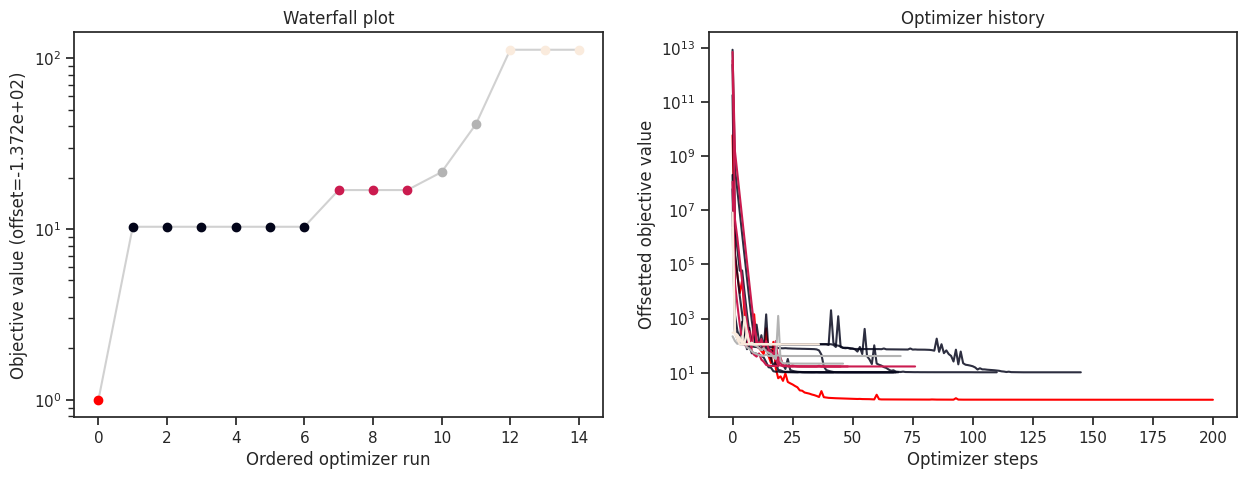
[19]:
print("History type: ", type(result.optimize_result.list[0].history))
# print("Function value trace of best run: ", result.optimize_result.list[0].history.get_fval_trace())
fig, ax = plt.subplots(1, 2)
visualize.waterfall(result, ax=ax[0])
visualize.optimizer_history(result, ax=ax[1])
fig.set_size_inches((15, 5))
History type: <class 'pypesto.history.memory.MemoryHistory'>
CSV History
The in-memory storage is, however, not stored anywhere. To do that, it is possible to store either to CSV or HDF5. This is specified via the storage_file option. If it ends in .csv, a pypesto.objective.history.CsvHistory will be employed; if it ends in .hdf5 a pypesto.objective.history.Hdf5History. Occurrences of the substring {id} in the filename are replaced by the multistart id, allowing to maintain a separate file per run (this is necessary for CSV as otherwise runs
are overwritten).
[20]:
%%time
# create temporary file
with tempfile.NamedTemporaryFile(suffix="_{id}.csv") as fn_csv:
# record the history and store to CSV
history_options = pypesto.HistoryOptions(
trace_record=True, storage_file=fn_csv.name
)
# Run optimizations
result = optimize.minimize(
problem=problem,
optimizer=optimizer,
n_starts=n_starts,
history_options=history_options,
filename=None,
)
CPU times: user 530 ms, sys: 4.09 ms, total: 534 ms
Wall time: 542 ms
Note that for this simple cost function, saving to CSV takes a considerable amount of time. This overhead decreases for more costly simulators, e.g., using ODE simulations via AMICI.
[21]:
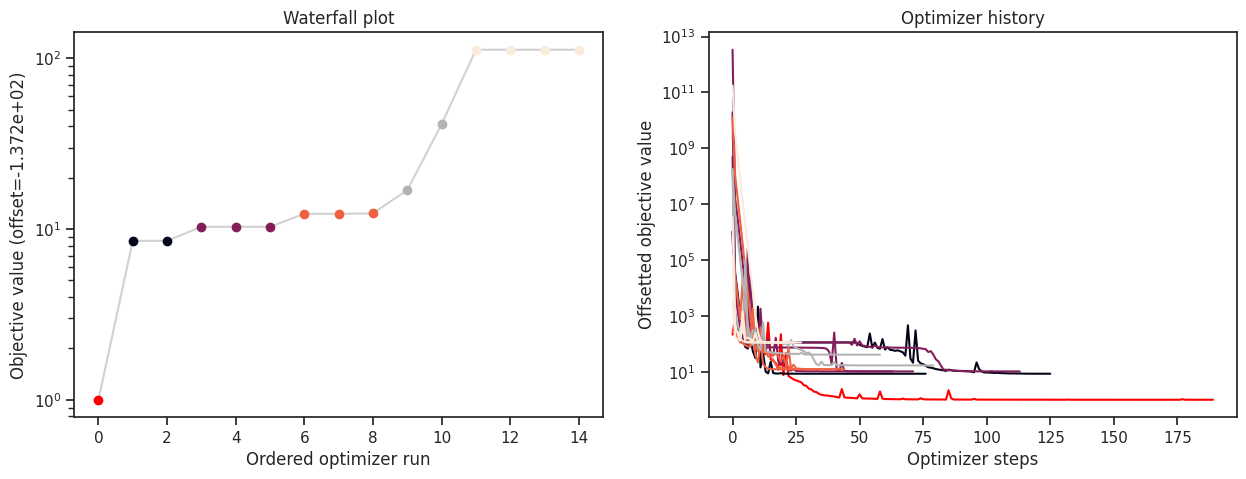
print("History type: ", type(result.optimize_result.list[0].history))
# print("Function value trace of best run: ", result.optimize_result.list[0].history.get_fval_trace())
fig, ax = plt.subplots(1, 2)
visualize.waterfall(result, ax=ax[0])
visualize.optimizer_history(result, ax=ax[1])
fig.set_size_inches((15, 5))
History type: <class 'pypesto.history.amici.CsvAmiciHistory'>
HDF5 History
Just as in CSV, writing the history to HDF5 takes a considerable amount of time. If a user specifies a HDF5 output file named my_results.hdf5 and uses a parallelization engine, then:
a folder is created to contain partial results, named
my_results/(the stem of the output filename)files are created to store the results of each start, named
my_results/my_results_{START_INDEX}.hdf5a file is created to store the combined result from all starts, named
my_results.hdf5. Note that this file depends on the files in themy_results/directory, so cease to function ifmy_results/is deleted.
[22]:
%%time
# create temporary file
f_hdf5 = tempfile.NamedTemporaryFile(suffix=".hdf5", delete=False)
fn_hdf5 = f_hdf5.name
# record the history and store to CSV
history_options = pypesto.HistoryOptions(
trace_record=True, storage_file=fn_hdf5
)
# Run optimizations
result = optimize.minimize(
problem=problem,
optimizer=optimizer,
n_starts=n_starts,
history_options=history_options,
filename=fn_hdf5,
)
CPU times: user 865 ms, sys: 75 ms, total: 940 ms
Wall time: 940 ms
[23]:
print("History type: ", type(result.optimize_result.list[0].history))
# print("Function value trace of best run: ", result.optimize_result.list[0].history.get_fval_trace())
fig, ax = plt.subplots(1, 2)
visualize.waterfall(result, ax=ax[0])
visualize.optimizer_history(result, ax=ax[1])
fig.set_size_inches((15, 5))
History type: <class 'pypesto.history.amici.Hdf5AmiciHistory'>
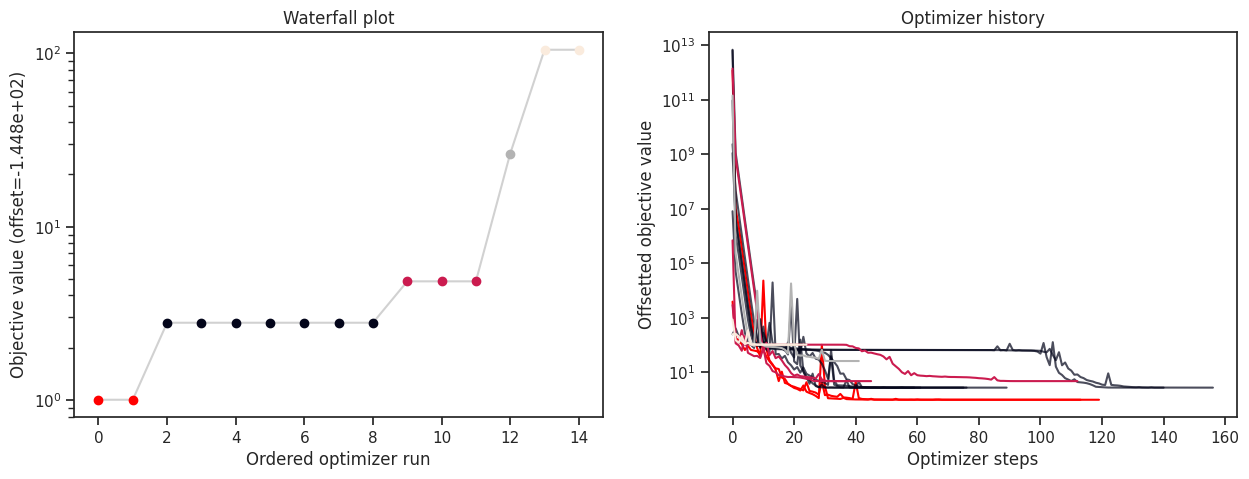
For the HDF5 history, it is possible to load the history from file, and to plot it, together with the optimization result.
[24]:
# load the history
result_loaded_w_history = pypesto.store.read_result(fn_hdf5)
fig, ax = plt.subplots(1, 2)
visualize.waterfall(result_loaded_w_history, ax=ax[0])
visualize.optimizer_history(result_loaded_w_history, ax=ax[1])
fig.set_size_inches((15, 5))
Loading the profiling result failed. It is highly likely that no profiling result exists within /tmp/tmp2s6_jj2g.hdf5.
Loading the sampling result failed. It is highly likely that no sampling result exists within /tmp/tmp2s6_jj2g.hdf5.

[25]:
# close the temporary file
f_hdf5.close()