AMICI in pyPESTO
After this notebook you can…
…create a pyPESTO problem directly from an AMICI model or through PEtab.
…perform parameter estimation of your amici model and adjust advanced settings for this.
…evaluate an optimization through basic visualizations.
…inspect parameter uncertainties through profile likelihoods and MCMC sampling.
To run optimizations and/or uncertainty analysis, we turn to pyPESTO (Parameter EStimation TOolbox for python).
pyPESTO is a Python tool for parameter estimation. It provides an interface to the model simulation tool AMICI for the simulation of Ordinary Differential Equation (ODE) models specified in the SBML format. With it, we can optimize our model parameters given measurement data, we can do uncertainty analysis via profile likelihoods and/or through sampling methods. pyPESTO provides an interface to many optimizers, global and local, such as e.g. SciPy optimizers, Fides and Pyswarm. Additionally, it interfaces samplers such as pymc, emcee and some of its own samplers.
[1]:
# import
import logging
import tempfile
from pprint import pprint
import amici
import amici.sim.sundials as asd
import matplotlib as mpl
import numpy as np
import petab
from IPython.display import Markdown, display
import pypesto
import pypesto.optimize as optimize
import pypesto.petab
import pypesto.profile as profile
import pypesto.sample as sample
import pypesto.store as store
import pypesto.visualize as visualize
import pypesto.visualize.model_fit as model_fit
mpl.rcParams["figure.dpi"] = 100
mpl.rcParams["font.size"] = 18
# Set seed for reproducibility
np.random.seed(1912)
# name of the model that will also be the name of the python module
model_name = "boehm_JProteomeRes2014"
# output directory
model_output_dir = "tmp/" + model_name
1. Create a pyPESTO problem
Create a pyPESTO objective from AMICI
Before we can use AMICI to simulate our model, the SBML model needs to be translated to C++ code. This is done by amici.SbmlImporter.
[2]:
sbml_file = f"./{model_name}/{model_name}.xml"
# Create an SbmlImporter instance for our SBML model
sbml_importer = amici.importers.sbml.SbmlImporter(sbml_file)
In this example, we want to specify fixed parameters, observables and a \(\sigma\) parameter. Unfortunately, the latter two are not part of the SBML standard. However, they can be provided to amici.importers.sbml.SbmlImporter.sbml2amici as demonstrated in the following.
Fixed parameters
Fixed parameters, i.e., parameters with respect to which no sensitivities are to be computed (these are often parameters specifying a certain experimental condition) are provided as a list of parameter IDs.
[3]:
fixed_parameters = ["ratio", "specC17"]
Observation model
We used SBML’s `AssignmentRule <https://sbml.org/software/libsbml/5.18.0/docs/formatted/python-api/classlibsbml_1_1_assignment_rule.html>`__ as a non-standard way to specify Model outputs within the SBML file. These rules need to be removed prior to the model import (AMICI does at this time not support these rules). This can be easily done using amici.assignment_rules_to_observables().
In this example, we introduced parameters named observable_* as targets of the observable AssignmentRules. Where applicable we have observable_*_sigma parameters for \(\sigma\) parameters.
[4]:
# Retrieve model output names and formulae from AssignmentRules and remove the respective rules
observables = amici.importers.sbml.assignment_rules_to_observables(
sbml_importer.sbml_model, # the libsbml model object
filter_function=lambda variable: (
variable.getId().startswith("observable_")
and not variable.getId().endswith("_sigma")
),
)
for observable in observables:
observable.sigma = "sd_" + observable.id.removeprefix("observable_")
print("Observables:")
pprint(observables)
Observables:
[MeasurementChannel(id_='observable_pSTAT5A_rel', name='observable_pSTAT5A_rel', formula='(100 * pApB + 200 * pApA * specC17) / (pApB + STAT5A * specC17 + 2 * pApA * specC17)', noise_distribution='normal', sigma='sd_pSTAT5A_rel', event_id=None),
MeasurementChannel(id_='observable_pSTAT5B_rel', name='observable_pSTAT5B_rel', formula='-(100 * pApB - 200 * pBpB * (specC17 - 1)) / (STAT5B * (specC17 - 1) - pApB + 2 * pBpB * (specC17 - 1))', noise_distribution='normal', sigma='sd_pSTAT5B_rel', event_id=None),
MeasurementChannel(id_='observable_rSTAT5A_rel', name='observable_rSTAT5A_rel', formula='(100 * pApB + 100 * STAT5A * specC17 + 200 * pApA * specC17) / (2 * pApB + STAT5A * specC17 + 2 * pApA * specC17 - STAT5B * (specC17 - 1) - 2 * pBpB * (specC17 - 1))', noise_distribution='normal', sigma='sd_rSTAT5A_rel', event_id=None)]
Generating the module
Now we can generate the python module for our model. SbmlImporter.sbml2amici will symbolically derive the sensitivity equations, generate C++ code for model simulation, and assemble the python module.
[5]:
%%time
sbml_importer.sbml2amici(
model_name,
model_output_dir,
verbose=False,
observation_model=observables,
fixed_parameters=fixed_parameters,
)
CPU times: user 1.65 s, sys: 44.3 ms, total: 1.69 s
Wall time: 12.1 s
[5]:
<amici._installation.amici.ModelPtr; proxy of <Swig Object of type 'std::unique_ptr< amici::Model > *' at 0x79c38eaff7f0> >
Importing the module and loading the model
If everything went well, we are ready to load the newly generated model:
[6]:
model_module = amici.import_model_module(model_name, model_output_dir)
Afterwards, we can get an instance of our model from which we can retrieve information such as parameter names:
[7]:
model = model_module.get_model()
print("Model parameters:", list(model.get_free_parameter_ids()))
print("Model outputs: ", list(model.get_observable_ids()))
print("Model states: ", list(model.get_state_ids()))
Model parameters: ['Epo_degradation_BaF3', 'k_exp_hetero', 'k_exp_homo', 'k_imp_hetero', 'k_imp_homo', 'k_phos', 'sd_pSTAT5A_rel', 'sd_pSTAT5B_rel', 'sd_rSTAT5A_rel']
Model outputs: ['observable_pSTAT5A_rel', 'observable_pSTAT5B_rel', 'observable_rSTAT5A_rel']
Model states: ['STAT5A', 'STAT5B', 'pApB', 'pApA', 'pBpB', 'nucpApA', 'nucpApB', 'nucpBpB']
Running simulations and analyzing results
After importing the model, we can run simulations using run_simulation. This requires a Model instance and a Solver instance. But, in order go gain a value of fit, we also need to provide some data.
[8]:
# we prepare our data as it is reported in the benchmark collection
# timepoints
timepoints = np.array(
[
0.0,
2.5,
5.0,
10.0,
15.0,
20.0,
30.0,
40.0,
50.0,
60.0,
80.0,
100.0,
120.0,
160.0,
200.0,
240.0,
]
)
# measurements
meas_pSTAT5A_rel = np.array(
[
7.901073,
66.363494,
81.171324,
94.730308,
95.116483,
91.441717,
91.257099,
93.672298,
88.754233,
85.269703,
81.132395,
76.135928,
65.248059,
42.599659,
25.157798,
15.430182,
]
)
meas_pSTAT5B_rel = np.array(
[
4.596533,
29.634546,
46.043806,
81.974734,
80.571609,
79.035720,
75.672380,
71.624720,
69.062863,
67.147384,
60.899476,
54.809258,
43.981290,
29.771458,
20.089017,
10.961845,
]
)
meas_rSTAT5A_rel = np.array(
[
14.723168,
33.762342,
36.799851,
49.717602,
46.928120,
47.836575,
46.928727,
40.597753,
43.783664,
44.457388,
41.327159,
41.062733,
39.235830,
36.619461,
34.893714,
32.211077,
]
)
[9]:
benchmark_parameters = np.array(
[
-1.568917588,
-4.999704894,
-2.209698782,
-1.786006548,
4.990114009,
4.197735488,
0.585755271,
0.818982819,
0.498684404,
]
)
# set timepoints for which we want to simulate the model
model.set_timepoints(timepoints)
# set fixed parameters for which we want to simulate the model
model.set_fixed_parameters(np.array([0.693, 0.107]))
# set parameters to optimal values found in the benchmark collection
model.set_parameter_scale(asd.ParameterScaling.log10)
model.set_free_parameters(benchmark_parameters)
# Create solver instance
solver = model.create_solver()
# Run simulation using model parameters from the benchmark collection and default solver options
rdata = asd.run_simulation(model, solver)
[10]:
# Create edata instance with dimensions and timepoints
edata = asd.ExpData(
3, # number of observables
0, # number of event outputs
0, # maximum number of events
timepoints, # timepoints
)
# set observed data
edata.set_measurements(meas_pSTAT5A_rel, 0)
edata.set_measurements(meas_pSTAT5B_rel, 1)
edata.set_measurements(meas_rSTAT5A_rel, 2)
# set standard deviations to optimal values found in the benchmark collection
edata.set_noise_scales(np.array(16 * [10**0.585755271]), 0)
edata.set_noise_scales(np.array(16 * [10**0.818982819]), 1)
edata.set_noise_scales(np.array(16 * [10**0.498684404]), 2)
[11]:
rdata = asd.run_simulation(model, solver, edata)
print("Chi2 value reported in benchmark collection: 47.9765479")
print(f"chi2 value using AMICI: {rdata['chi2']}")
Chi2 value reported in benchmark collection: 47.9765479
chi2 value using AMICI: 47.97654319310132
Creating pyPESTO objective
We are now set up to create our pyPESTO objective. This objective is a vital part of the pyPESTO infrastructure as it provides a blackbox interface to call any predefined objective function with some parameters and evaluate it. We can easily create an AmiciObjective by supplying the model, an amici solver and the data.
Keep in mind, however, that you can use ANY function you would like for this.
[12]:
# we make some more adjustments to our model and the solver
model.require_sensitivities_for_all_parameters()
solver.set_sensitivity_method(asd.SensitivityMethod.forward)
solver.set_sensitivity_order(asd.SensitivityOrder.first)
objective = pypesto.AmiciObjective(
amici_model=model, amici_solver=solver, edatas=[edata], max_sensi_order=1
)
We can now call the objective function directly for any parameter. The value that is put out is the likelihood function. If we want to interact more with the AMICI returns, we can also return this by call and e.g., retrieve the chi2 value.
[13]:
# the generic objective call
print(f"Objective value: {objective(benchmark_parameters)}")
# a call returning the AMICI data as well
obj_call_with_dict = objective(benchmark_parameters, return_dict=True)
print(
f"Chi^2 value of the same parameters: {obj_call_with_dict['rdatas'][0]['chi2']}"
)
Objective value: 138.22199735603812
Chi^2 value of the same parameters: 47.97654319310132
Now this makes the whole process already somewhat easier, but still, getting here took us quite some coding and effort. This will only get more complicated, the more complex the model is. Therefore, in the next part, we will show you how to bypass the tedious lines of code by using PEtab.
Create a pyPESTO problem + objective from Petab
Background on PEtab

pyPESTO supports the PEtab standard. PEtab is a data format for specifying parameter estimation problems in systems biology.
A PEtab problem consist of an SBML file, defining the model topology and a set of .tsv files, defining experimental conditions, observables, measurements and parameters (and their optimization bounds, scale, priors…). All files that make up a PEtab problem can be structured in a .yaml file. The pypesto.Objective coming from a PEtab problem corresponds to the negative-log-likelihood/negative-log-posterior distribution of the parameters.
For more details on PEtab, the interested reader is referred to PEtab’s format definition, for examples the reader is referred to the PEtab benchmark collection. For demonstration purposes, a simple model of conversion-reaction will be used as the running example throughout this notebook.
[14]:
%%capture
petab_yaml = f"./{model_name}/{model_name}.yaml"
petab_problem = petab.Problem.from_yaml(petab_yaml)
importer = pypesto.petab.PetabImporter(petab_problem)
problem = importer.create_problem(verbose=False)
Compiling amici model to folder /home/docs/checkouts/readthedocs.org/user_builds/pypesto/checkouts/latest/doc/example/amici_models/1.0.1/FullModel.
2026-03-18 12:49:15.063 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - PEtab mapping: ({}, {'Epo_degradation_BaF3': 'Epo_degradation_BaF3', 'k_exp_hetero': 'k_exp_hetero', 'k_exp_homo': 'k_exp_homo', 'k_imp_hetero': 'k_imp_hetero', 'k_imp_homo': 'k_imp_homo', 'k_phos': 'k_phos', 'ratio': 'ratio', 'sd_pSTAT5A_rel': 'sd_pSTAT5A_rel', 'sd_pSTAT5B_rel': 'sd_pSTAT5B_rel', 'sd_rSTAT5A_rel': 'sd_rSTAT5A_rel', 'specC17': 'specC17', 'noiseParameter1_pSTAT5A_rel': 'sd_pSTAT5A_rel', 'noiseParameter1_pSTAT5B_rel': 'sd_pSTAT5B_rel', 'noiseParameter1_rSTAT5A_rel': 'sd_rSTAT5A_rel'}, {}, {'Epo_degradation_BaF3': 'log10', 'k_exp_hetero': 'log10', 'k_exp_homo': 'log10', 'k_imp_hetero': 'log10', 'k_imp_homo': 'log10', 'k_phos': 'log10', 'ratio': 'lin', 'sd_pSTAT5A_rel': 'log10', 'sd_pSTAT5B_rel': 'log10', 'sd_rSTAT5A_rel': 'log10', 'specC17': 'lin', 'noiseParameter1_pSTAT5A_rel': 'log10', 'noiseParameter1_pSTAT5B_rel': 'log10', 'noiseParameter1_rSTAT5A_rel': 'log10'})
2026-03-18 12:49:15.064 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Fixed parameters pre-equilibration: {}
2026-03-18 12:49:15.064 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Fixed parameters simulation: {'ratio': 'ratio', 'specC17': 'specC17'}
2026-03-18 12:49:15.064 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Variable parameters pre-equilibration: {}
2026-03-18 12:49:15.065 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Variable parameters simulation: {'Epo_degradation_BaF3': 'Epo_degradation_BaF3', 'k_exp_hetero': 'k_exp_hetero', 'k_exp_homo': 'k_exp_homo', 'k_imp_hetero': 'k_imp_hetero', 'k_imp_homo': 'k_imp_homo', 'k_phos': 'k_phos', 'sd_pSTAT5A_rel': 'sd_pSTAT5A_rel', 'sd_pSTAT5B_rel': 'sd_pSTAT5B_rel', 'sd_rSTAT5A_rel': 'sd_rSTAT5A_rel', 'noiseParameter1_pSTAT5A_rel': 'sd_pSTAT5A_rel', 'noiseParameter1_pSTAT5B_rel': 'sd_pSTAT5B_rel', 'noiseParameter1_rSTAT5A_rel': 'sd_rSTAT5A_rel'}
2026-03-18 12:49:15.066 - amici.sim.sundials.petab.v1._parameter_mapping - DEBUG - Merged: {'Epo_degradation_BaF3': 'Epo_degradation_BaF3', 'k_exp_hetero': 'k_exp_hetero', 'k_exp_homo': 'k_exp_homo', 'k_imp_hetero': 'k_imp_hetero', 'k_imp_homo': 'k_imp_homo', 'k_phos': 'k_phos', 'sd_pSTAT5A_rel': 'sd_pSTAT5A_rel', 'sd_pSTAT5B_rel': 'sd_pSTAT5B_rel', 'sd_rSTAT5A_rel': 'sd_rSTAT5A_rel', 'noiseParameter1_pSTAT5A_rel': 'sd_pSTAT5A_rel', 'noiseParameter1_pSTAT5B_rel': 'sd_pSTAT5B_rel', 'noiseParameter1_rSTAT5A_rel': 'sd_rSTAT5A_rel'}
[15]:
# Check the dataframes. First the parameter dataframe
petab_problem.parameter_df.head()
[15]:
| parameterName | parameterScale | lowerBound | upperBound | nominalValue | estimate | |
|---|---|---|---|---|---|---|
| parameterId | ||||||
| Epo_degradation_BaF3 | EPO_{degradation,BaF3} | log10 | 0.00001 | 100000 | 0.026983 | 1 |
| k_exp_hetero | k_{exp,hetero} | log10 | 0.00001 | 100000 | 0.000010 | 1 |
| k_exp_homo | k_{exp,homo} | log10 | 0.00001 | 100000 | 0.006170 | 1 |
| k_imp_hetero | k_{imp,hetero} | log10 | 0.00001 | 100000 | 0.016368 | 1 |
| k_imp_homo | k_{imp,homo} | log10 | 0.00001 | 100000 | 97749.379402 | 1 |
[16]:
# Check the observable dataframe
petab_problem.observable_df.head()
[16]:
| observableName | observableFormula | noiseFormula | observableTransformation | noiseDistribution | |
|---|---|---|---|---|---|
| observableId | |||||
| pSTAT5A_rel | NaN | (100 * pApB + 200 * pApA * specC17) / (pApB + ... | noiseParameter1_pSTAT5A_rel | lin | normal |
| pSTAT5B_rel | NaN | -(100 * pApB - 200 * pBpB * (specC17 - 1)) / (... | noiseParameter1_pSTAT5B_rel | lin | normal |
| rSTAT5A_rel | NaN | (100 * pApB + 100 * STAT5A * specC17 + 200 * p... | noiseParameter1_rSTAT5A_rel | lin | normal |
[17]:
# Check the measurement dataframe
petab_problem.measurement_df.head()
[17]:
| observableId | preequilibrationConditionId | simulationConditionId | measurement | time | observableParameters | noiseParameters | datasetId | |
|---|---|---|---|---|---|---|---|---|
| 0 | pSTAT5A_rel | NaN | model1_data1 | 7.901073 | 0.0 | NaN | sd_pSTAT5A_rel | model1_data1_pSTAT5A_rel |
| 1 | pSTAT5A_rel | NaN | model1_data1 | 66.363494 | 2.5 | NaN | sd_pSTAT5A_rel | model1_data1_pSTAT5A_rel |
| 2 | pSTAT5A_rel | NaN | model1_data1 | 81.171324 | 5.0 | NaN | sd_pSTAT5A_rel | model1_data1_pSTAT5A_rel |
| 3 | pSTAT5A_rel | NaN | model1_data1 | 94.730308 | 10.0 | NaN | sd_pSTAT5A_rel | model1_data1_pSTAT5A_rel |
| 4 | pSTAT5A_rel | NaN | model1_data1 | 95.116483 | 15.0 | NaN | sd_pSTAT5A_rel | model1_data1_pSTAT5A_rel |
[18]:
# check the condition dataframe
petab_problem.condition_df.head()
[18]:
| conditionName | |
|---|---|
| conditionId | |
| model1_data1 | condition1 |
This was really straightforward. With this, we are still able to do all the same things we did before and also adjust solver setting, change the model, etc.
[19]:
# call the objective function
print(f"Objective value: {problem.objective(petab_problem.x_free_indices)}")
# change things in the model
problem.objective.amici_model.require_sensitivities_for_all_parameters()
# change solver settings
print(
f"Absolute tolerance before change: {problem.objective.amici_solver.get_absolute_tolerance()}"
)
problem.objective.amici_solver.set_absolute_tolerance(1e-15)
print(
f"Absolute tolerance after change: {problem.objective.amici_solver.get_absolute_tolerance()}"
)
Objective value: 928.3017253039851
Absolute tolerance before change: 1e-16
Absolute tolerance after change: 1e-15
Now we are good to go and start the first optimization.
2. Optimization
Once setup, the optimization can be done very quickly with default settings. If needed, these settings can be highly individualized and change according to the needs of our model. In this section, we shall go over some of these settings.
Optimizer
The optimizer determines the algorithm with which we optimize our model. The main disjunction is between global and local optimizers.
pyPESTO provides an interface to many optimizers, such as Fides, ScipyOptimizers, Pyswarm and many more. For a whole list of supported optimizers with settings for each optimizer you can have a look here.
[20]:
optimizer_options = {"maxiter": 1e4, "fatol": 1e-12, "frtol": 1e-12}
optimizer = optimize.FidesOptimizer(
options=optimizer_options, verbose=logging.WARN
)
History options
In some cases, it is good to trace what the optimizer did in each step, i.e., the history. There is a multitude of options on what to report here, but the most important one is trace_record which turns the history function on and off.
[21]:
# save optimizer trace
history_options = pypesto.HistoryOptions(trace_record=True)
Startpoint method
The startpoint method describes how you want to choose your startpoints, in case you do a multistart optimization. The default here is uniform meaning that each startpoint is a uniform sample from the allowed parameter space. The other two notable options are either latin_hypercube or a self-defined function. The startpoint method is an inherent attribute of the problem and can be set there.
[22]:
problem.startpoint_method = pypesto.startpoint.uniform
Optimization options
Some further possible options for the optimization. Notably allow_failed_starts, which in case of a very complicated objective function, can help get to the desired number of optimizations when turned off. As we do not need this here, we create the default options.
[23]:
opt_options = optimize.OptimizeOptions()
opt_options
[23]:
{'allow_failed_starts': True,
'report_sres': True,
'report_hess': True,
'history_beats_optimizer': True}
Running the optimization
We now only need to decide on the number of starts as well as the engine we want to use for the optimization.
[24]:
n_starts = 20 # usually a value >= 100 should be used
engine = pypesto.engine.MultiProcessEngine()
Engine will use up to 2 processes (= CPU count).
[25]:
%%time
result = optimize.minimize(
problem=problem,
optimizer=optimizer,
n_starts=n_starts,
engine=engine,
options=opt_options,
)
2026-03-18 12:49:15.444 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 87.8679 and h = 1.69508e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:15.447 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 87.8679: AMICI failed to integrate the forward problem
2026-03-18 12:49:15.612 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 137.571 and h = 6.50828e-06, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:15.614 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 137.571: AMICI failed to integrate the forward problem
2026-03-18 12:49:15.704 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 84.9284 and h = 1.47218e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:15.706 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 84.9284: AMICI failed to integrate the forward problem
2026-03-18 12:49:16 fides(WARNING) Stopping as trust region radius 2.17E-16 is smaller than machine precision.
2026-03-18 12:49:16 fides(WARNING) Stopping as trust region radius 1.24E-16 is smaller than machine precision.
2026-03-18 12:49:16.983 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 146.559 and h = 3.27065e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:16.985 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 146.559: AMICI failed to integrate the forward problem
2026-03-18 12:49:17 fides(WARNING) Stopping as trust region radius 6.44E-17 is smaller than machine precision.
2026-03-18 12:49:17.496 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 89.0459 and h = 1.48475e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:17.499 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 89.0459: AMICI failed to integrate the forward problem
2026-03-18 12:49:17 fides(WARNING) Stopping as trust region radius 1.34E-16 is smaller than machine precision.
2026-03-18 12:49:17.835 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 88.8693 and h = 1.14434e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:17.838 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 88.8693: AMICI failed to integrate the forward problem
2026-03-18 12:49:17.956 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 88.8341 and h = 2.32245e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:17.958 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 88.8341: AMICI failed to integrate the forward problem
2026-03-18 12:49:18.292 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 88.8106 and h = 1.12867e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:18.296 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 88.8106: AMICI failed to integrate the forward problem
2026-03-18 12:49:18 fides(WARNING) Stopping as trust region radius 2.22E-16 is smaller than machine precision.
2026-03-18 12:49:19 fides(WARNING) Stopping as trust region radius 8.08E-17 is smaller than machine precision.
2026-03-18 12:49:19 fides(WARNING) Stopping as trust region radius 1.85E-16 is smaller than machine precision.
2026-03-18 12:49:19.557 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 90.6425 and h = 2.60191e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:19.560 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 90.6425: AMICI failed to integrate the forward problem
2026-03-18 12:49:19.727 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 146.26 and h = 3.31307e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:19.730 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 146.26: AMICI failed to integrate the forward problem
2026-03-18 12:49:19.869 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 145.587 and h = 3.56638e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:19.871 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 145.587: AMICI failed to integrate the forward problem
2026-03-18 12:49:20 fides(WARNING) Stopping as trust region radius 1.26E-16 is smaller than machine precision.
2026-03-18 12:49:20 fides(WARNING) Stopping as trust region radius 9.96E-17 is smaller than machine precision.
2026-03-18 12:49:20.650 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 144.978 and h = 2.61828e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:20.653 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 144.978: AMICI failed to integrate the forward problem
2026-03-18 12:49:20 fides(WARNING) Stopping as trust region radius 2.22E-16 is smaller than machine precision.
2026-03-18 12:49:20.701 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 146.012 and h = 2.74092e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:20.704 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 146.012: AMICI failed to integrate the forward problem
2026-03-18 12:49:20 fides(WARNING) Stopping as trust region radius 1.11E-16 is smaller than machine precision.
2026-03-18 12:49:21.539 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 145.564 and h = 2.72071e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:21.542 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 145.564: AMICI failed to integrate the forward problem
2026-03-18 12:49:21.585 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 145.315 and h = 4.77711e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:21.587 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 145.315: AMICI failed to integrate the forward problem
2026-03-18 12:49:21.659 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 145.594 and h = 2.49353e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:21.662 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 145.594: AMICI failed to integrate the forward problem
2026-03-18 12:49:21 fides(WARNING) Stopping as trust region radius 1.66E-16 is smaller than machine precision.
2026-03-18 12:49:21 fides(WARNING) Stopping as trust region radius 6.90E-17 is smaller than machine precision.
2026-03-18 12:49:22 fides(WARNING) Stopping as trust region radius 5.90E-17 is smaller than machine precision.
2026-03-18 12:49:23.693 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 23.9702 and h = 1.93323e-06, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:23.695 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 23.9702: AMICI failed to integrate the forward problem
2026-03-18 12:49:23.914 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 145.684 and h = 2.29599e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:23.917 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 145.684: AMICI failed to integrate the forward problem
2026-03-18 12:49:24 fides(WARNING) Stopping as trust region radius 1.39E-16 is smaller than machine precision.
2026-03-18 12:49:24.556 - amici.sim.sundials._swig_wrappers - DEBUG - [model1_data1][cvodes:cvHandleFailure:ERR_FAILURE] At t = 168.816 and h = 2.86471e-05, the error test failed repeatedly or with |h| = hmin.
2026-03-18 12:49:24.558 - amici.sim.sundials._swig_wrappers - ERROR - [model1_data1][FORWARD_FAILURE] AMICI forward simulation failed at t = 168.816: AMICI failed to integrate the forward problem
2026-03-18 12:49:24 fides(WARNING) Stopping as trust region radius 1.11E-16 is smaller than machine precision.
2026-03-18 12:49:25 fides(WARNING) Stopping as trust region radius 2.11E-16 is smaller than machine precision.
2026-03-18 12:49:26 fides(WARNING) Stopping as trust region radius 1.06E-16 is smaller than machine precision.
2026-03-18 12:49:26 fides(WARNING) Stopping as trust region radius 7.58E-17 is smaller than machine precision.
CPU times: user 70.8 ms, sys: 41.7 ms, total: 113 ms
Wall time: 11.2 s
Now as a first step after the optimization, we can take a look at the summary of the optimizer:
[26]:
display(Markdown(result.summary()))
Optimization Result
number of starts: 20
best value: 145.75943605211032, id=17
worst value: 249.74599566317698, id=3
number of non-finite values: 0
execution time summary:
Mean execution time: 1.071s
Maximum execution time: 3.107s, id=15
Minimum execution time: 0.506s, id=3
summary of optimizer messages:
Count
Message
19
Trust Region Radius too small to proceed
1
Converged according to fval difference
best value found (approximately) 1 time(s)
number of plateaus found: 3
A summary of the best run:
Optimizer Result
optimizer used: <FidesOptimizer hessian_update=default verbose=30 options={‘maxiter’: 10000.0, ‘fatol’: 1e-12, ‘frtol’: 1e-12}>
message: Trust Region Radius too small to proceed
number of evaluations: 136
time taken to optimize: 0.868s
startpoint: [-2.59120601 0.69656874 -3.88289712 -1.74846428 -1.58175173 3.39830011 0.0917892 -0.85030875 -3.77417568]
endpoint: [-1.52346177 -4.99913434 -2.0344487 -1.83079474 -1.67385293 3.94118998 0.5077889 0.80381426 0.79609226]
final objective value: 145.75943605211032
final gradient value: [ 6.28878531e-03 2.80952447e-02 2.95933803e-03 1.51013868e-02 2.96689611e-03 -6.20342667e-03 4.33106041e-04 -4.94011743e-04 -2.06238070e-05]
final hessian value: [[ 2.37396953e+03 3.59626422e-01 2.64653686e+02 2.61613981e+03 8.75310630e+02 -8.65016195e+02 6.90811997e+01 -4.51850083e+01 -2.39106718e+01] [ 3.59626422e-01 2.96209064e-04 2.94176953e-02 3.65290075e-01 1.60744104e-01 -1.70796449e-01 -1.80206161e-04 -2.71001704e-02 -3.74113151e-02] [ 2.64653686e+02 2.94176953e-02 7.03218002e+01 2.78167030e+02 1.49612981e+02 -1.35643717e+02 -3.39780810e+00 -3.44823085e-01 3.73581706e+00] [ 2.61613981e+03 3.65290075e-01 2.78167030e+02 2.91434348e+03 9.22004965e+02 -8.64693706e+02 8.16016304e+01 -4.77364755e+01 -3.38999271e+01] [ 8.75310630e+02 1.60744104e-01 1.49612981e+02 9.22004965e+02 4.25471731e+02 -4.03091143e+02 9.19037602e+00 -1.99746603e+01 1.07774527e+01] [-8.65016195e+02 -1.70796449e-01 -1.35643717e+02 -8.64693706e+02 -4.03091143e+02 1.14624404e+03 -2.12541829e+01 -1.23836049e+01 3.36520717e+01] [ 6.90811997e+01 -1.80206161e-04 -3.39780810e+00 8.16016304e+01 9.19037602e+00 -2.12541829e+01 8.48293725e+01 0.00000000e+00 0.00000000e+00] [-4.51850083e+01 -2.71001704e-02 -3.44823085e-01 -4.77364755e+01 -1.99746603e+01 -1.23836049e+01 0.00000000e+00 8.48315073e+01 0.00000000e+00] [-2.39106718e+01 -3.74113151e-02 3.73581706e+00 -3.38999271e+01 1.07774527e+01 3.36520717e+01 0.00000000e+00 0.00000000e+00 8.48304173e+01]]
We can see some informative statistics, such as the mean execution time, best and worst values, a small table on the exit messages of the optimizer as well as detailed info on the best optimizer.
As our best start is just as good as the reported benchmark value, we shall now further inspect the result thorough some useful visualisations.
3. Optimization visualization
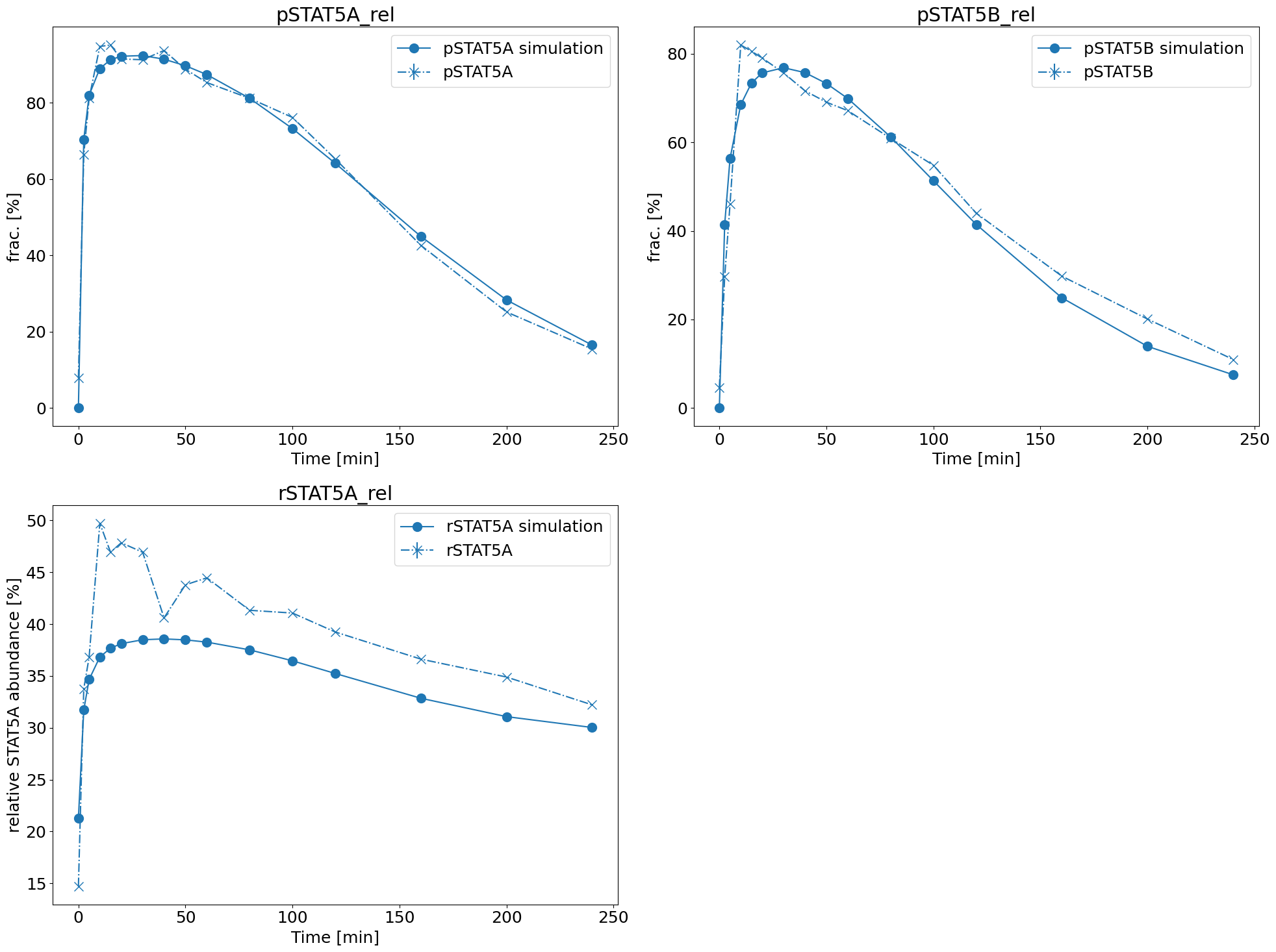
Model fit
Probably the most useful visualization there is, is one, where we visualize the found parameter dynamics against the measurements. This way we can see whether the fit is qualitatively and/or quantitatively good.
[27]:
ax = model_fit.visualize_optimized_model_fit(
petab_problem=petab_problem, result=result, pypesto_problem=problem
)
Waterfall plot
The waterfall plot is a visualization of the final objective function values of each start. They are sorted from small to high and then plotted. Similar values will get clustered and get the same color.
This helps to determine whether the result is reproducible and whether we reliably found a local minimum that we hope to be the global one.
[28]:
visualize.waterfall(result);
Parameter plots
To visualize the parameters, there is a multitude of options:
Parameter overview
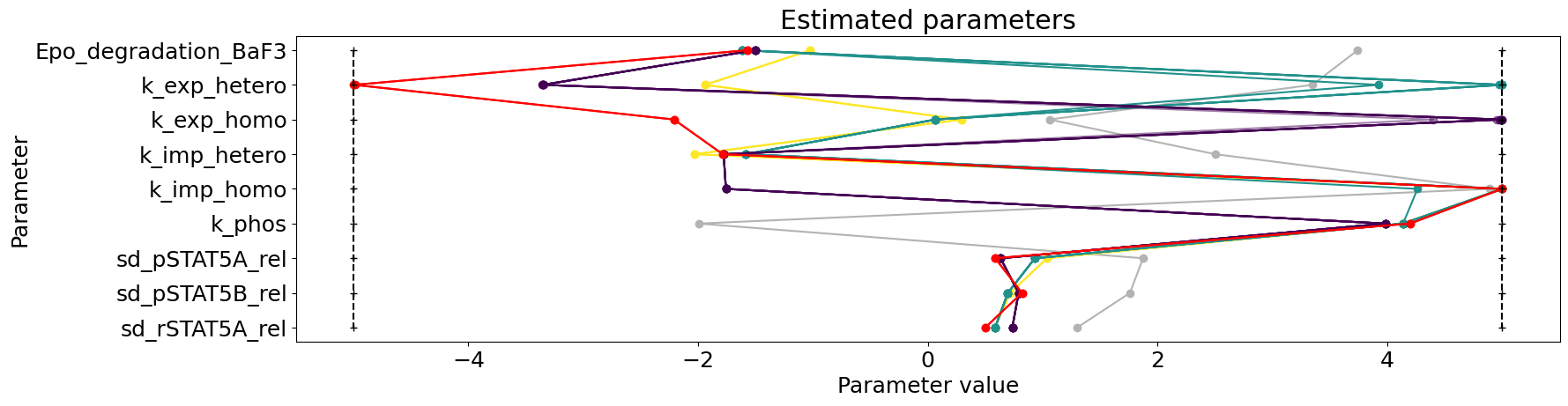
Here we plot the parameters of all starts within their bounds. This can tell us whether some bounds are always hit and might need to be questioned and if the best starts are similar or differ amongst themselves, hinting already for some non-identifiabilities.
[29]:
visualize.parameters(result);
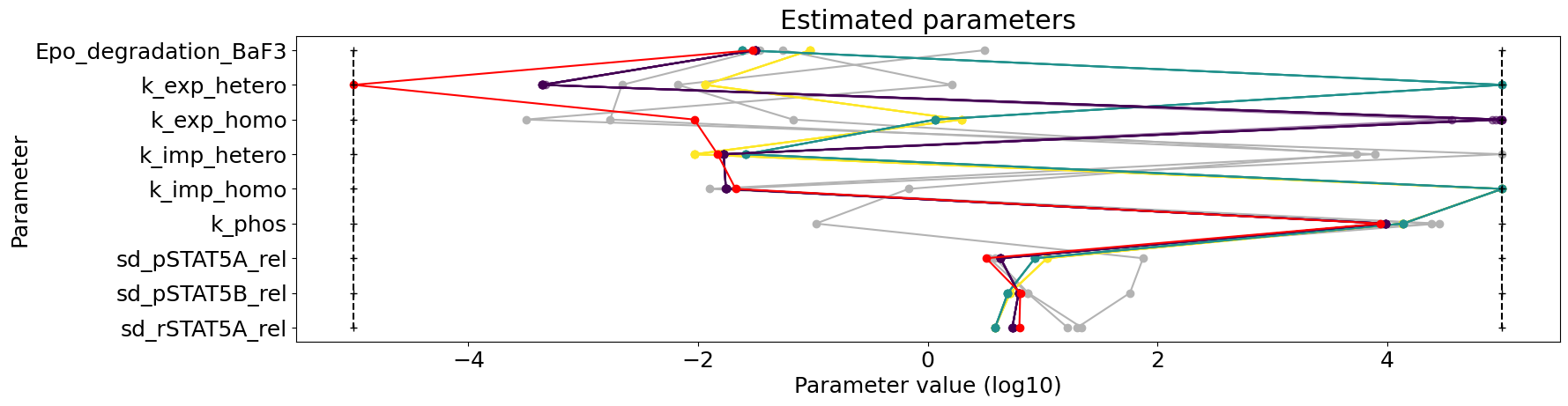
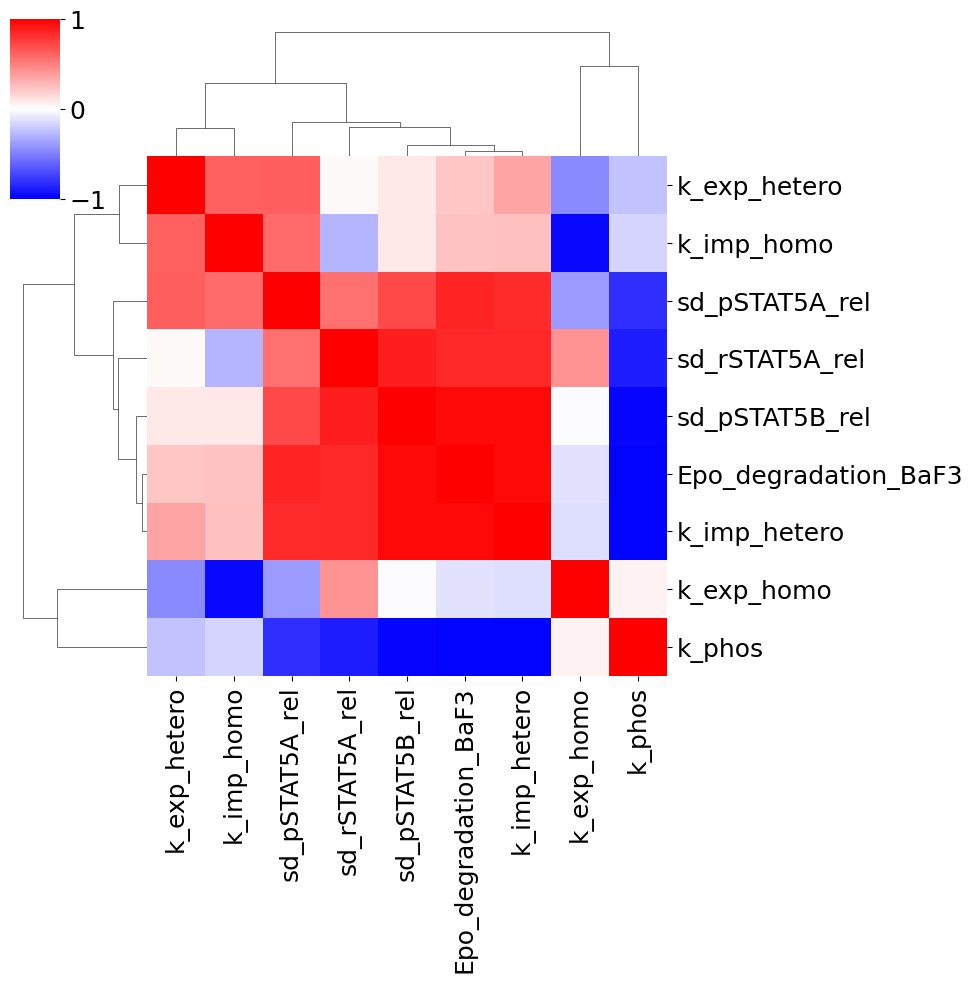
Parameter correlation plot
To further look into possible uncertainties, we can plot the correlation of the final points. Sometimes, pairs of parameters are dependent on each other and fixing one might solve some non-identifiability.
[30]:
visualize.parameters_correlation_matrix(result);
Parameter histogram + scatter
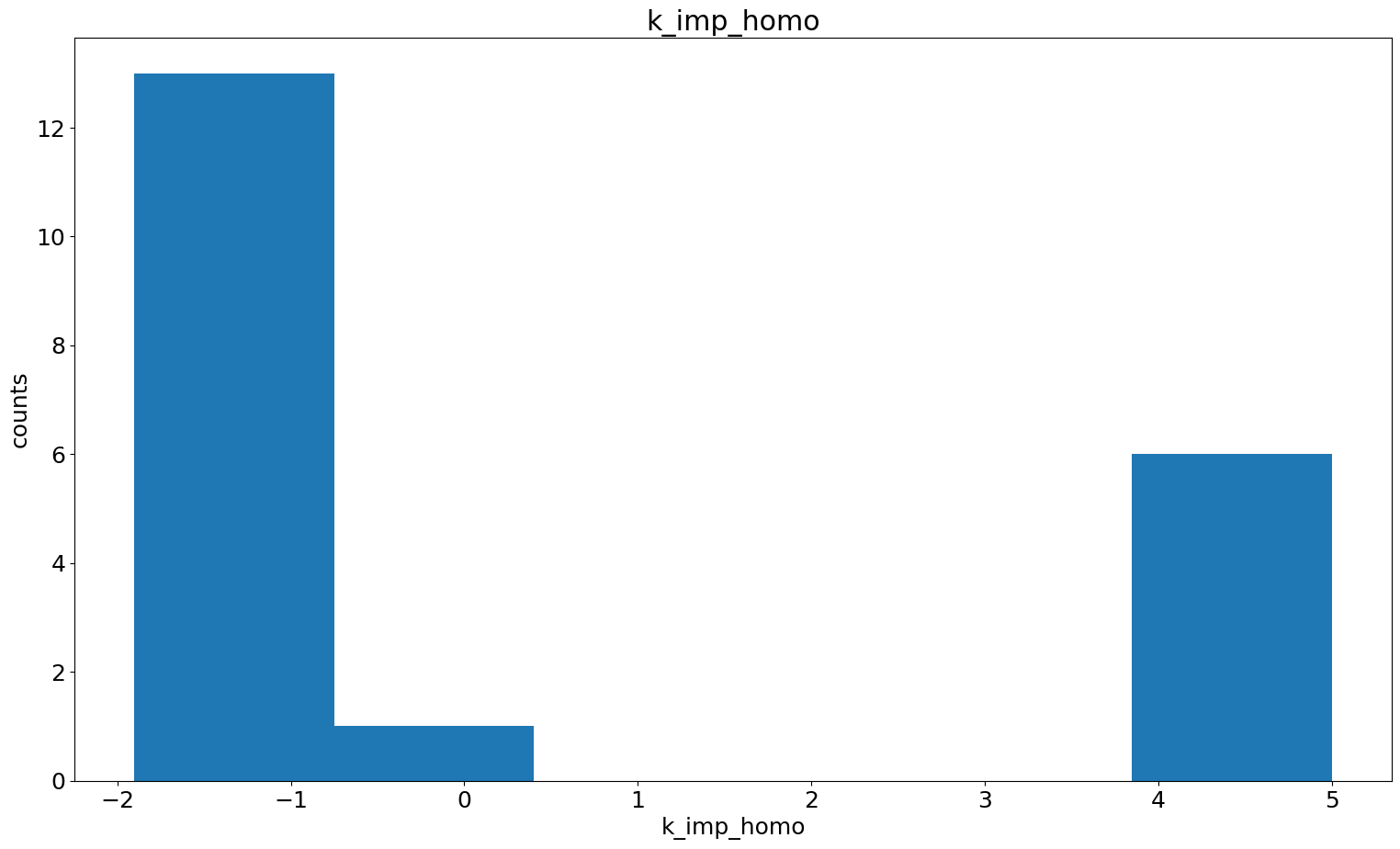
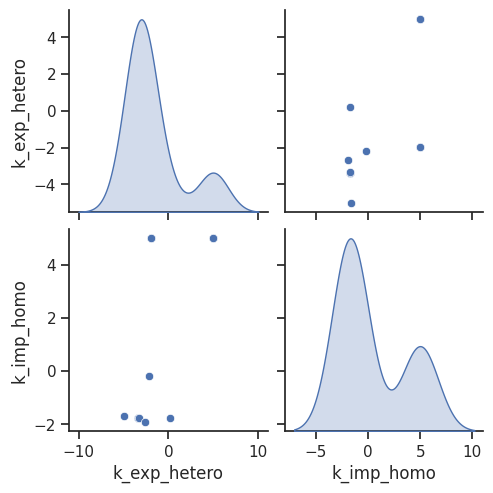
In case we found some dependencies and for further investigation, we can also specifically look at the histograms of certain parameters and the pairwise parameter scatter plot.
[31]:
visualize.parameter_hist(result=result, parameter_name="k_exp_hetero")
visualize.parameter_hist(result=result, parameter_name="k_imp_homo");
[32]:
visualize.optimization_scatter(result, parameter_indices=[1, 4]);
However, these visualizations are only an indicator for possible uncertainties. In the next section we turn to proper uncertainty quantification.
4. Uncertainty quantification
This mainly consists of two parts:
Profile Likelihoods
MCMC sampling
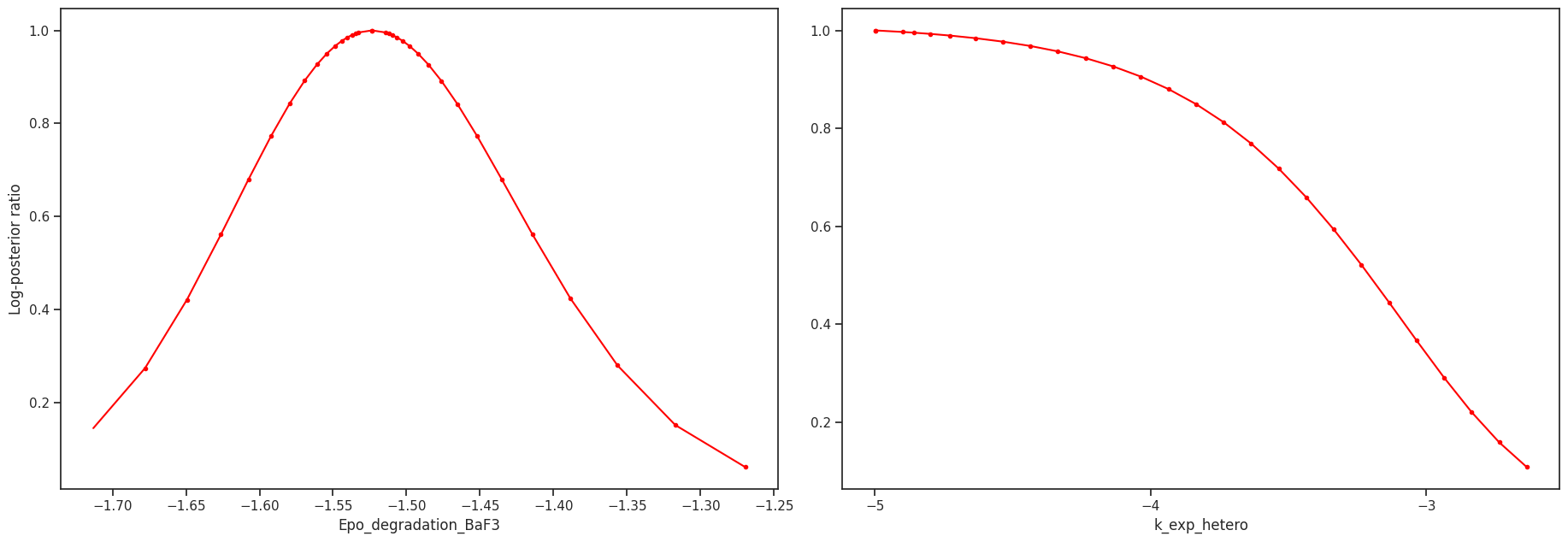
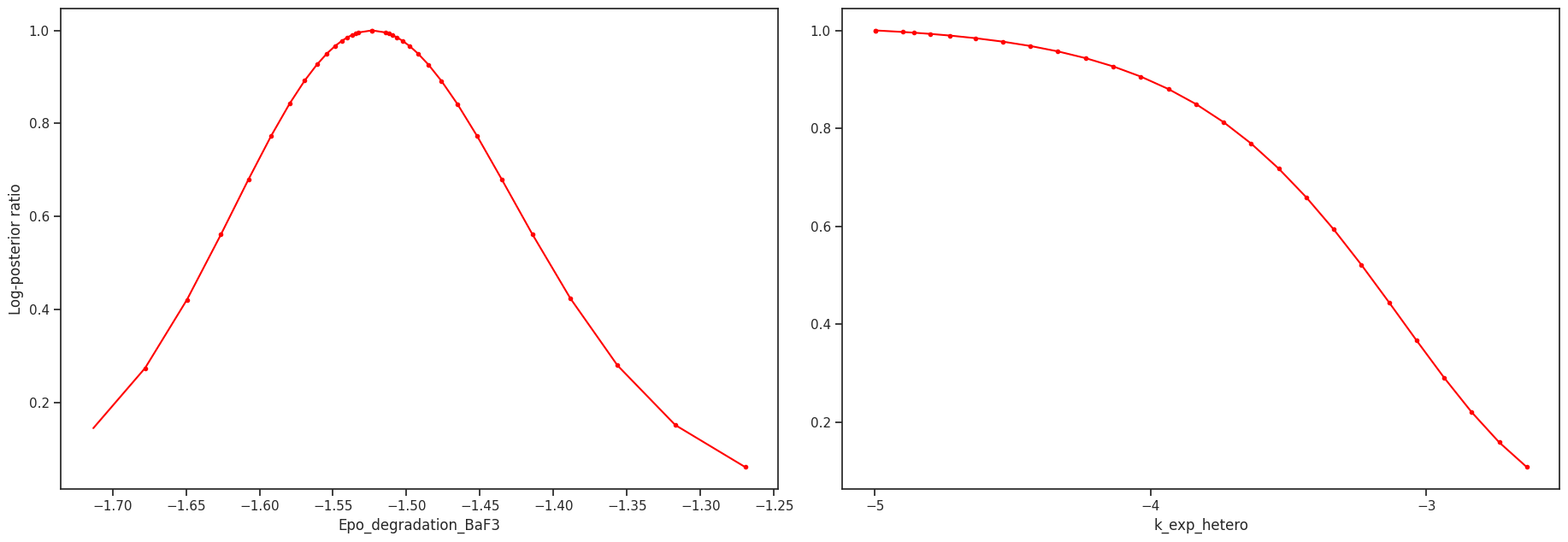
Profile likelihood
The profile likelihood uses an optimization scheme to calculate the confidence intervals for each parameter. We start with the best found parameter set of the optimization. Then in each step, we increase/decrease the parameter of interest, fix it and then run one local optimization. We do this until we either hit the bounds or reach a sufficiently bad fit.
To run the profiling, we do not need a lot of setup, as we did this already for the optimization.
[33]:
%%time
result = profile.parameter_profile(
problem=problem,
result=result,
optimizer=optimizer,
engine=engine,
profile_index=[0, 1],
)
2026-03-18 12:49:28 fides(WARNING) Stopping as trust region radius 1.18E-16 is smaller than machine precision.
2026-03-18 12:49:28 fides(WARNING) Stopping as trust region radius 1.43E-16 is smaller than machine precision.
2026-03-18 12:49:28 fides(WARNING) Stopping as trust region radius 1.52E-16 is smaller than machine precision.
2026-03-18 12:49:28 fides(WARNING) Stopping as trust region radius 1.07E-16 is smaller than machine precision.
2026-03-18 12:49:28 fides(WARNING) Stopping as trust region radius 9.52E-17 is smaller than machine precision.
2026-03-18 12:49:28 fides(WARNING) Stopping as trust region radius 6.28E-17 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 1.71E-16 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 1.23E-16 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 1.15E-16 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 2.05E-16 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 1.32E-16 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 8.08E-17 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 1.86E-16 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 6.65E-17 is smaller than machine precision.
2026-03-18 12:49:29 fides(WARNING) Stopping as trust region radius 7.53E-17 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 8.67E-17 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 6.88E-17 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 8.49E-17 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 6.48E-17 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 1.23E-16 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 2.17E-16 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 7.03E-17 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 8.68E-17 is smaller than machine precision.
2026-03-18 12:49:30 fides(WARNING) Stopping as trust region radius 7.61E-17 is smaller than machine precision.
2026-03-18 12:49:31 fides(WARNING) Stopping as trust region radius 1.41E-16 is smaller than machine precision.
2026-03-18 12:49:31 fides(WARNING) Stopping as trust region radius 1.13E-16 is smaller than machine precision.
2026-03-18 12:49:31 fides(WARNING) Stopping as trust region radius 8.03E-17 is smaller than machine precision.
2026-03-18 12:49:31 fides(WARNING) Stopping as trust region radius 6.47E-17 is smaller than machine precision.
2026-03-18 12:49:31 fides(WARNING) Stopping as trust region radius 1.37E-16 is smaller than machine precision.
2026-03-18 12:49:31 fides(WARNING) Stopping as trust region radius 1.32E-16 is smaller than machine precision.
2026-03-18 12:49:31 fides(WARNING) Stopping as trust region radius 6.23E-17 is smaller than machine precision.
2026-03-18 12:49:32 fides(WARNING) Stopping as trust region radius 1.31E-16 is smaller than machine precision.
2026-03-18 12:49:32 fides(WARNING) Stopping as trust region radius 1.16E-16 is smaller than machine precision.
2026-03-18 12:49:32 fides(WARNING) Stopping as trust region radius 1.55E-16 is smaller than machine precision.
2026-03-18 12:49:32 fides(WARNING) Stopping as trust region radius 8.13E-17 is smaller than machine precision.
2026-03-18 12:49:32 fides(WARNING) Stopping as trust region radius 1.19E-16 is smaller than machine precision.
2026-03-18 12:49:32 fides(WARNING) Stopping as trust region radius 7.65E-17 is smaller than machine precision.
2026-03-18 12:49:33 fides(WARNING) Stopping as trust region radius 6.62E-17 is smaller than machine precision.
2026-03-18 12:49:33 fides(WARNING) Stopping as trust region radius 1.14E-16 is smaller than machine precision.
2026-03-18 12:49:33 fides(WARNING) Stopping as trust region radius 1.54E-16 is smaller than machine precision.
2026-03-18 12:49:33 fides(WARNING) Stopping as trust region radius 9.50E-17 is smaller than machine precision.
2026-03-18 12:49:33 fides(WARNING) Stopping as trust region radius 1.89E-16 is smaller than machine precision.
2026-03-18 12:49:34 fides(WARNING) Stopping as trust region radius 1.60E-16 is smaller than machine precision.
2026-03-18 12:49:34 fides(WARNING) Stopping as trust region radius 1.33E-16 is smaller than machine precision.
2026-03-18 12:49:34 fides(WARNING) Stopping as trust region radius 1.90E-16 is smaller than machine precision.
2026-03-18 12:49:34 fides(WARNING) Stopping as trust region radius 6.66E-17 is smaller than machine precision.
2026-03-18 12:49:35 fides(WARNING) Stopping as trust region radius 9.57E-17 is smaller than machine precision.
2026-03-18 12:49:35 fides(WARNING) Stopping as trust region radius 7.68E-17 is smaller than machine precision.
2026-03-18 12:49:35 fides(WARNING) Stopping as trust region radius 1.10E-16 is smaller than machine precision.
2026-03-18 12:49:35 fides(WARNING) Stopping as trust region radius 1.87E-16 is smaller than machine precision.
2026-03-18 12:49:36 fides(WARNING) Stopping as trust region radius 6.10E-17 is smaller than machine precision.
2026-03-18 12:49:36 fides(WARNING) Stopping as trust region radius 1.35E-16 is smaller than machine precision.
2026-03-18 12:49:36 fides(WARNING) Stopping as trust region radius 8.81E-17 is smaller than machine precision.
2026-03-18 12:49:37 fides(WARNING) Stopping as trust region radius 1.62E-16 is smaller than machine precision.
2026-03-18 12:49:37 fides(WARNING) Stopping as trust region radius 9.87E-17 is smaller than machine precision.
2026-03-18 12:49:37 fides(WARNING) Stopping as trust region radius 1.00E-16 is smaller than machine precision.
2026-03-18 12:49:37 fides(WARNING) Stopping as trust region radius 1.20E-16 is smaller than machine precision.
2026-03-18 12:49:38 fides(WARNING) Stopping as trust region radius 1.09E-16 is smaller than machine precision.
2026-03-18 12:49:38 fides(WARNING) Stopping as trust region radius 6.91E-17 is smaller than machine precision.
CPU times: user 42.6 ms, sys: 42.1 ms, total: 84.7 ms
Wall time: 10.5 s
We can visualize the profiles directly
[34]:
# plot profiles
pypesto.visualize.profiles(result);
Sampling
We can use MCMC sampling to get a distribution on the posterior of the parameters. Here again, we do not need a lot of setup. We only need to define a sampler, of which pyPESTO offers a multitude.
[35]:
# Sampling
sampler = sample.AdaptiveMetropolisSampler()
result = sample.sample(
problem=problem,
sampler=sampler,
n_samples=1000,
result=result,
)
Elapsed time: 0.7670316150000005
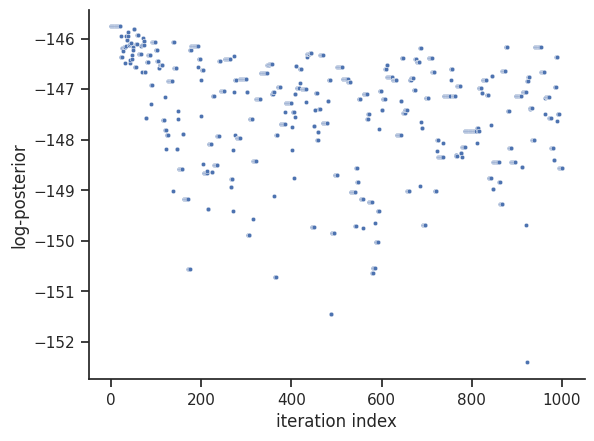
For visualization purposes, we can visualize the trace of the objective function value, as well as a scatter plot of the parameters, just like in the optimization. We do omit the scatter plot here, as it has a very large size.
[36]:
# plot objective function trace
visualize.sampling_fval_traces(result);
/home/docs/checkouts/readthedocs.org/user_builds/pypesto/envs/latest/lib/python3.13/site-packages/pypesto/visualize/sampling.py:78: UserWarning: Burn in index not found in the results, the full chain will be shown.
You may want to use, e.g., `pypesto.sample.geweke_test`.
_, params_fval, _, _, _ = get_data_to_plot(
[37]:
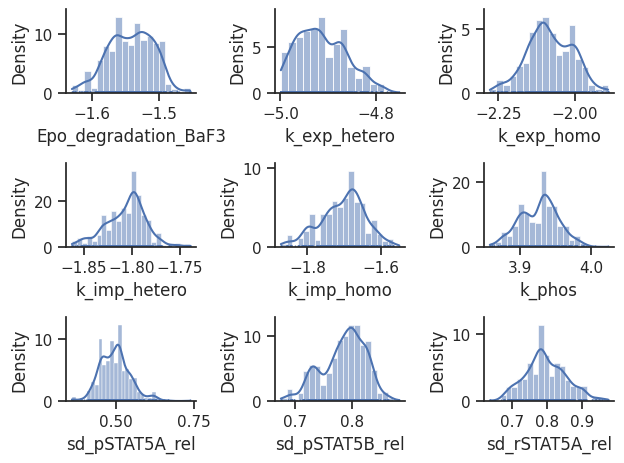
visualize.sampling_1d_marginals(result);
/home/docs/checkouts/readthedocs.org/user_builds/pypesto/envs/latest/lib/python3.13/site-packages/pypesto/visualize/sampling.py:1291: UserWarning: Burn in index not found in the results, the full chain will be shown.
You may want to use, e.g., `pypesto.sample.geweke_test`.
nr_params, params_fval, theta_lb, theta_ub, param_names = get_data_to_plot(
5. Saving results
Lastly, the whole process took quite some time, but is not necessarily finished. It is therefore very useful, to be able to save the result as is. pyPESTO uses the HDF5 format, and with two very short commands we are able to read and write a result from and to an HDF5 file.
Save result object in HDF5 File
[38]:
# create temporary file
fn = tempfile.NamedTemporaryFile(suffix=".hdf5", delete=False)
# write result with write_result function.
# Choose which parts of the result object to save with
# corresponding booleans.
store.write_result(
result=result,
filename=fn.name,
problem=True,
optimize=True,
sample=True,
profile=True,
)
Reload results
[39]:
# Read result
result2 = store.read_result(fn, problem=True)
# close file
fn.close()
As the warning already suggests, we need to assign the problem again correctly.
[40]:
result2.problem = problem
Now we are able to quickly load the results and visualize them.
Plot (reloaded) results
[41]:
# plot profiles
pypesto.visualize.profiles(result2);