A sampler study
In this notebook, we perform a short study of how various samplers implemented in pyPESTO perform.
[1]:
# install if not done yet
# !apt install libatlas-base-dev swig
# %pip install pypesto[amici,petab,pymc,emcee] --quiet
The pipeline
First, we show a typical workflow, fully integrating the samplers with a PEtab problem, using a toy example of a conversion reaction.
[1]:
import petab
import pypesto
import pypesto.optimize as optimize
import pypesto.petab
import pypesto.sample as sample
import pypesto.visualize as visualize
# import to petab
petab_problem = petab.Problem.from_yaml(
"conversion_reaction/conversion_reaction.yaml"
)
# import to pypesto
importer = pypesto.petab.PetabImporter(petab_problem)
# create problem
problem = importer.create_problem()
Commonly, as a first step, optimization is performed, in order to find good parameter point estimates.
[2]:
result = optimize.minimize(problem, n_starts=10, filename=None)
100%|███████████████████████████████████████████| 10/10 [00:00<00:00, 10.31it/s]
[3]:
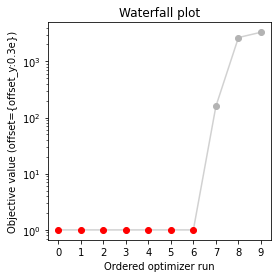
visualize.waterfall(result, size=(4, 4));
Next, we perform sampling. Here, we employ a pypesto.sample.AdaptiveParallelTemperingSampler sampler, which runs Markov Chain Monte Carlo (MCMC) chains on different temperatures. For each chain, we employ a pypesto.sample.AdaptiveMetropolisSampler. For more on the samplers see below or the API documentation.
[4]:
sampler = sample.AdaptiveParallelTemperingSampler(
internal_sampler=sample.AdaptiveMetropolisSampler(), n_chains=3
)
For the actual sampling, we call the pypesto.sample.sample function. By passing the result object to the function, the previously found global optimum is used as starting point for the MCMC sampling.
[5]:
%%time
result = sample.sample(
problem, n_samples=5000, sampler=sampler, result=result, filename=None
)
100%|██████████████████████████████████████| 5000/5000 [00:12<00:00, 407.76it/s]
Elapsed time: 15.599733418
CPU times: user 12.7 s, sys: 2.88 s, total: 15.6 s
Wall time: 12.3 s
When the sampling is finished, we can analyse our results. A first thing to do is to analyze the sampling burn-in:
[6]:
sample.geweke_test(result)
Geweke burn-in index: 0
[6]:
0
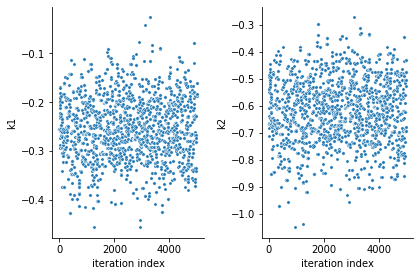
pyPESTO provides functions to analyse both the sampling process as well as the obtained sampling result. Visualizing the traces e.g. allows to detect burn-in phases, or fine-tune hyperparameters. First, the parameter trajectories can be visualized:
[7]:
ax = visualize.sampling_parameter_traces(result, use_problem_bounds=False)
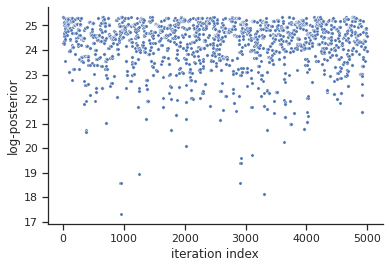
Next, also the log posterior trace can be visualized:
[8]:
ax = visualize.sampling_fval_traces(result)
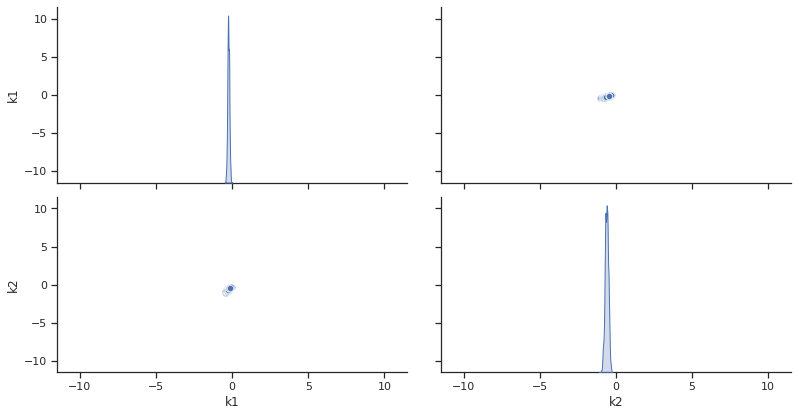
To visualize the result, there are various options. The scatter plot shows histograms of 1-dim parameter marginals and scatter plots of 2-dimensional parameter combinations:
[9]:
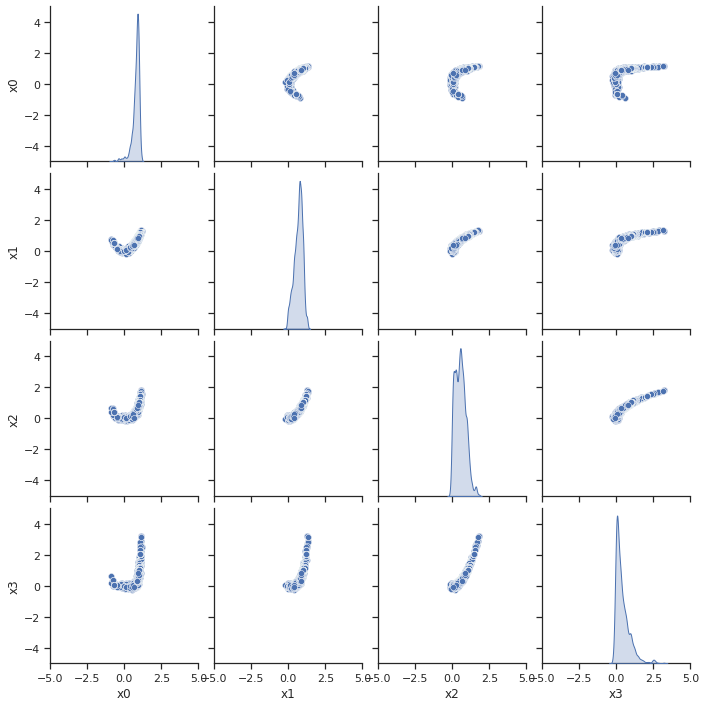
ax = visualize.sampling_scatter(result, size=[13, 6])
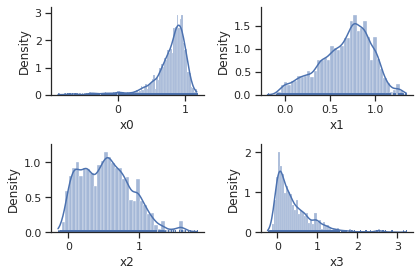
sampling_1d_marginals allows to plot e.g. kernel density estimates or histograms (internally using seaborn):
[10]:
for i_chain in range(len(result.sample_result.betas)):
visualize.sampling_1d_marginals(
result, i_chain=i_chain, suptitle=f"Chain: {i_chain}"
)
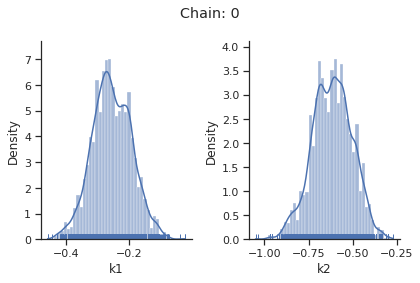
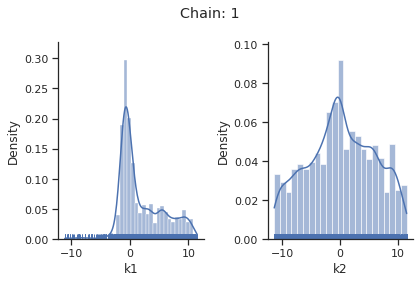
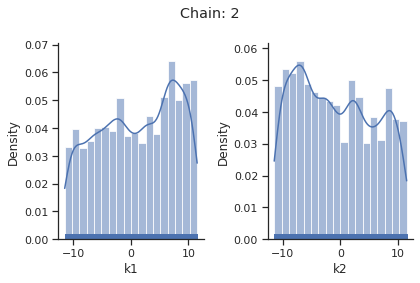
That’s it for the moment on using the sampling pipeline.
1-dim test problem
To compare and test the various implemented samplers, we first study a 1-dimensional test problem of a gaussian mixture density, together with a flat prior.
[11]:
import numpy as np
import seaborn as sns
from scipy.stats import multivariate_normal
import pypesto
import pypesto.sample as sample
import pypesto.visualize as visualize
def density(x):
return 0.3 * multivariate_normal.pdf(
x, mean=-1.5, cov=0.1
) + 0.7 * multivariate_normal.pdf(x, mean=2.5, cov=0.2)
def nllh(x):
return -np.log(density(x))
objective = pypesto.Objective(fun=nllh)
problem = pypesto.Problem(objective=objective, lb=-4, ub=5, x_names=["x"])
The likelihood has two separate modes:
[12]:
xs = np.linspace(-4, 5, 100)
ys = [density(x) for x in xs]
ax = sns.lineplot(x=xs, y=ys, color="C1")
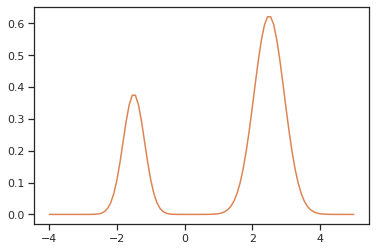
Metropolis sampler
For this problem, let us try out the simplest sampler, the pypesto.sample.MetropolisSampler.
[13]:
sampler = sample.MetropolisSampler({"std": 0.5})
result = sample.sample(
problem, 1e4, sampler, x0=np.array([0.5]), filename=None
)
100%|███████████████████████████████████| 10000/10000 [00:01<00:00, 7190.13it/s]
Elapsed time: 1.5156195930000003
[14]:
sample.geweke_test(result)
ax = visualize.sampling_1d_marginals(result)
ax[0][0].plot(xs, ys)
Geweke burn-in index: 0
[14]:
[<matplotlib.lines.Line2D at 0x7f4e48d43d30>]
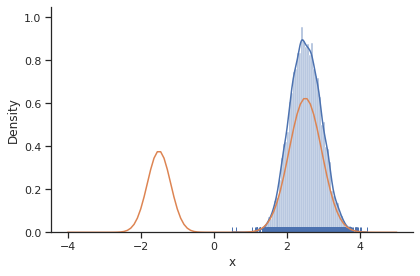
The obtained posterior does not accurately represent the distribution, often only capturing one mode. This is because it is hard for the Markov chain to jump between the distribution’s two modes. This can be fixed by choosing a higher proposal variation std:
[15]:
sampler = sample.MetropolisSampler({"std": 1})
result = sample.sample(
problem, 1e4, sampler, x0=np.array([0.5]), filename=None
)
100%|███████████████████████████████████| 10000/10000 [00:01<00:00, 6954.75it/s]
Elapsed time: 1.5859449810000008
[16]:
sample.geweke_test(result)
ax = visualize.sampling_1d_marginals(result)
ax[0][0].plot(xs, ys)
Geweke burn-in index: 1500
[16]:
[<matplotlib.lines.Line2D at 0x7f4e387e8370>]
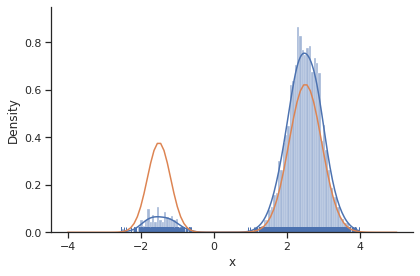
In general, MCMC have difficulties exploring multimodel landscapes. One way to overcome this is to used parallel tempering. There, various chains are run, lifting the densities to different temperatures. At high temperatures, proposed steps are more likely to get accepted and thus jumps between modes more likely.
Parallel tempering sampler
In pyPESTO, the most basic parallel tempering algorithm is the pypesto.sample.ParallelTemperingSampler. It takes an internal_sampler parameter, to specify what sampler to use for performing sampling the different chains. Further, we can directly specify what inverse temperatures betas to use. When not specifying the betas explicitly but just the number of chains n_chains, an established near-exponential decay scheme is used.
[17]:
sampler = sample.ParallelTemperingSampler(
internal_sampler=sample.MetropolisSampler(), betas=[1, 1e-1, 1e-2]
)
result = sample.sample(
problem, 1e4, sampler, x0=np.array([0.5]), filename=None
)
100%|███████████████████████████████████| 10000/10000 [00:04<00:00, 2094.53it/s]
Elapsed time: 4.978559487000002
[18]:
sample.geweke_test(result)
for i_chain in range(len(result.sample_result.betas)):
visualize.sampling_1d_marginals(
result, i_chain=i_chain, suptitle=f"Chain: {i_chain}"
)
Geweke burn-in index: 0
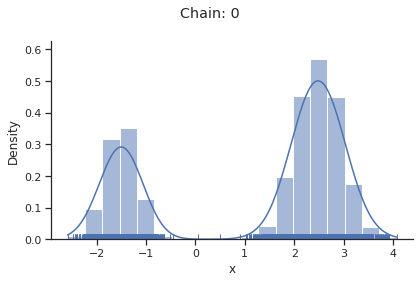
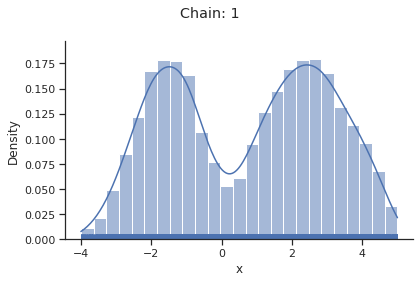
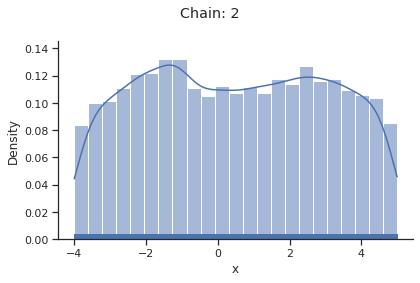
Of interest is here finally the first chain at index i_chain=0, which approximates the posterior well.
Adaptive Metropolis sampler
The problem of having to specify the proposal step variation manually can be overcome by using the pypesto.sample.AdaptiveMetropolisSampler, which iteratively adjusts the proposal steps to the function landscape.
[19]:
sampler = sample.AdaptiveMetropolisSampler()
result = sample.sample(
problem, 1e4, sampler, x0=np.array([0.5]), filename=None
)
100%|███████████████████████████████████| 10000/10000 [00:01<00:00, 5438.35it/s]
Elapsed time: 1.8583142600000002
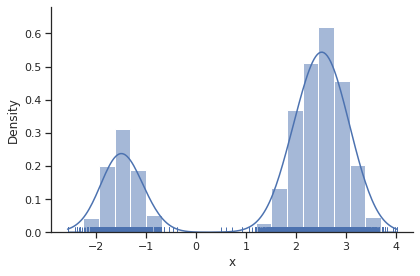
[20]:
sample.geweke_test(result)
ax = visualize.sampling_1d_marginals(result)
Geweke burn-in index: 0
Adaptive parallel tempering sampler
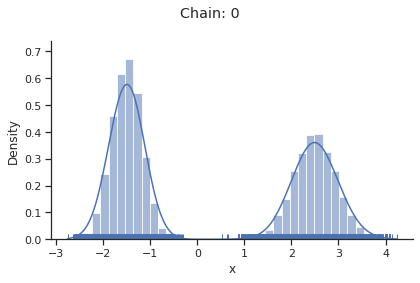
The pypesto.sample.AdaptiveParallelTemperingSampler iteratively adjusts the temperatures to obtain good swapping rates between chains.
[21]:
sampler = sample.AdaptiveParallelTemperingSampler(
internal_sampler=sample.AdaptiveMetropolisSampler(), n_chains=3
)
result = sample.sample(
problem, 1e4, sampler, x0=np.array([0.5]), filename=None
)
100%|███████████████████████████████████| 10000/10000 [00:05<00:00, 1685.18it/s]
Elapsed time: 5.989867801999999
[22]:
sample.geweke_test(result)
for i_chain in range(len(result.sample_result.betas)):
visualize.sampling_1d_marginals(
result, i_chain=i_chain, suptitle=f"Chain: {i_chain}"
)
Geweke burn-in index: 0
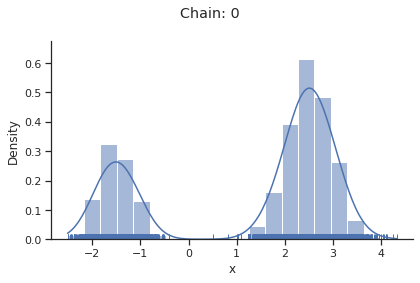
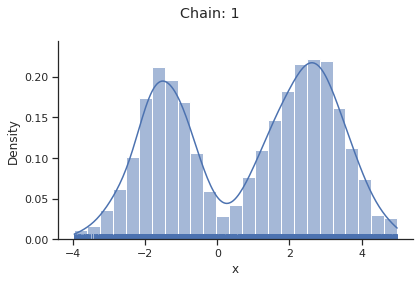
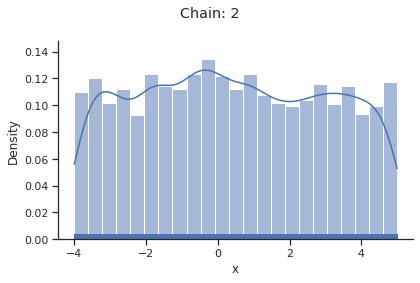
[23]:
result.sample_result.betas
[23]:
array([1.00000000e+00, 2.14050647e-01, 2.00000000e-05])
Pymc sampler
[24]:
from pypesto.sample.pymc import PymcSampler
sampler = PymcSampler()
result = sample.sample(
problem, 1e4, sampler, x0=np.array([0.5]), filename=None
)
hwloc/linux: Ignoring PCI device with non-16bit domain.
Pass --enable-32bits-pci-domain to configure to support such devices
(warning: it would break the library ABI, don't enable unless really needed).
hwloc/linux: Ignoring PCI device with non-16bit domain.
Pass --enable-32bits-pci-domain to configure to support such devices
(warning: it would break the library ABI, don't enable unless really needed).
Sequential sampling (1 chains in 1 job)
Slice: [x]
Sampling 1 chain for 1_000 tune and 10_000 draw iterations (1_000 + 10_000 draws total) took 14 seconds.
Elapsed time: 14.028044278999992
[25]:
sample.geweke_test(result)
for i_chain in range(len(result.sample_result.betas)):
visualize.sampling_1d_marginals(
result, i_chain=i_chain, suptitle=f"Chain: {i_chain}"
)
Geweke burn-in index: 0
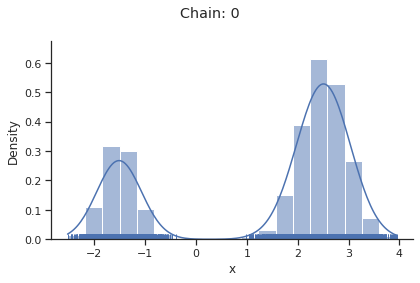
If not specified, pymc chooses an adequate sampler automatically.
Emcee sampler
[26]:
sampler = sample.EmceeSampler(nwalkers=10, run_args={"progress": True})
result = sample.sample(
problem, int(1e4), sampler, x0=np.array([0.5]), filename=None
)
100%|████████████████████████████████████| 10000/10000 [00:14<00:00, 705.98it/s]
Elapsed time: 14.25610228699999
[27]:
sample.geweke_test(result)
for i_chain in range(len(result.sample_result.betas)):
visualize.sampling_1d_marginals(
result, i_chain=i_chain, suptitle=f"Chain: {i_chain}"
)
Geweke burn-in index: 10000
2-dim test problem: Rosenbrock banana
The adaptive parallel tempering sampler with chains running adaptive Metropolis samplers is also able to sample from more challenging posterior distributions. To illustrates this shortly, we use the Rosenbrock function.
[28]:
import scipy.optimize as so
import pypesto
# first type of objective
objective = pypesto.Objective(fun=so.rosen)
dim_full = 4
lb = -5 * np.ones((dim_full, 1))
ub = 5 * np.ones((dim_full, 1))
problem = pypesto.Problem(objective=objective, lb=lb, ub=ub)
[29]:
sampler = sample.AdaptiveParallelTemperingSampler(
internal_sampler=sample.AdaptiveMetropolisSampler(), n_chains=10
)
result = sample.sample(
problem, 1e4, sampler, x0=np.zeros(dim_full), filename=None
)
100%|████████████████████████████████████| 10000/10000 [00:15<00:00, 635.62it/s]
Elapsed time: 15.791353567999991
[30]:
sample.geweke_test(result)
ax = visualize.sampling_scatter(result)
ax = visualize.sampling_1d_marginals(result)
Geweke burn-in index: 500